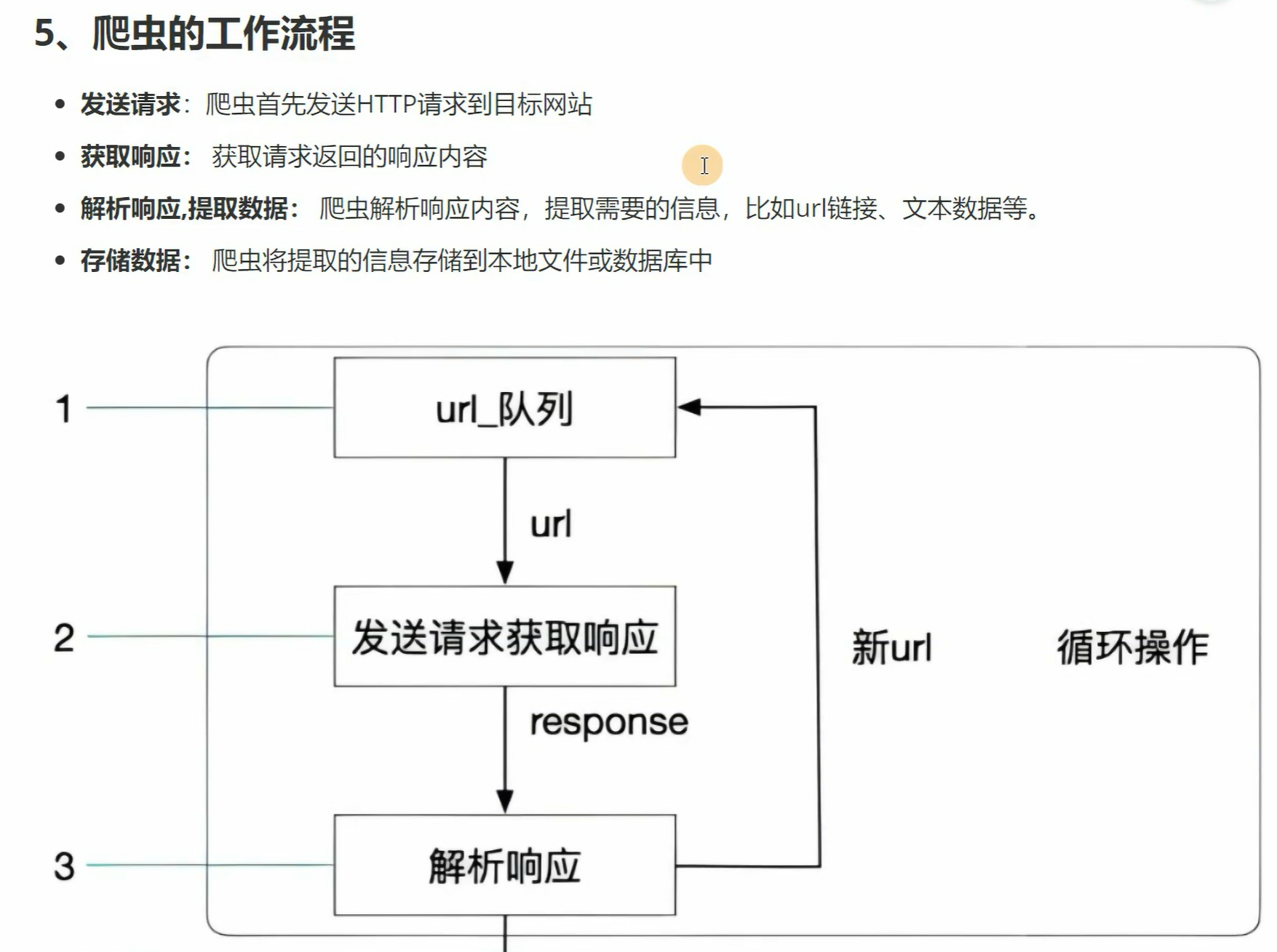
爬虫进阶 爬虫一定要找最新的教程,因为网站更新速度很快,老版教程很可能会过时,一些案例基本无法复现
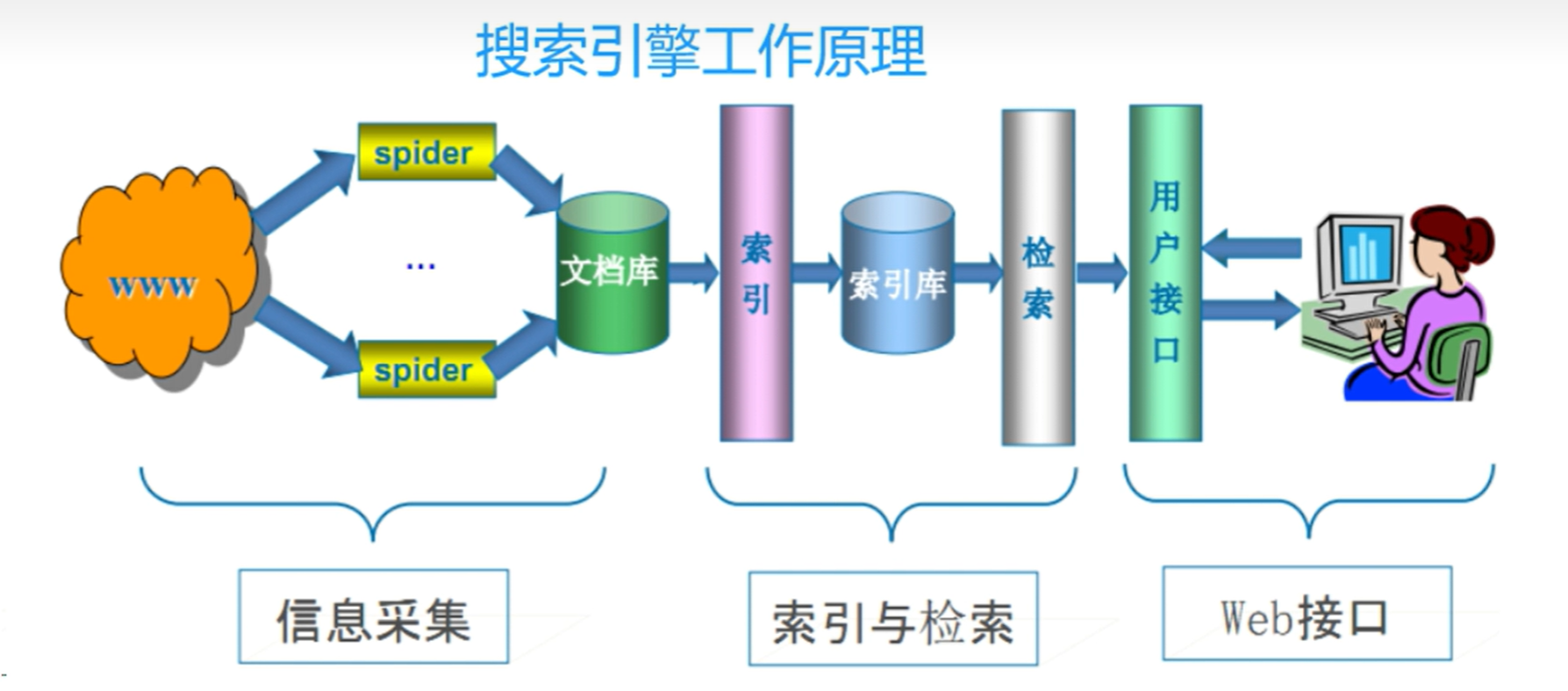
爬虫概述
静态页面抓取:
获取构造需要抓取的所有url列表
遍历这个列表,使用request等抓取页面数据
使用xpath+Scrapy Selector或者Xpath+lxml的方式对抓取的页面内容进行解析
xpath的编写可以借助浏览器来完成,选中对应元素右键点击copy as xpath
request构造请求:
get请求:
方式一:url+参数拼接方式
方式二:url+params形参的方式
post请求
许多登陆页面,需要通过构造post请求,提交信息,破除限制
可以通过form-data或者json的形式提交数据
模拟登陆场景: 许多网站必须登陆之后才能访问里面其他的页面
通过抓包,找到登陆接口
编写代码请求登陆接口,传入正确的账号、密码等信息
即使登陆之后,仍然可以访问其他页面吗?不一定,这时我们要关注后台的鉴权方式
后台的鉴权方式一般有两种:
基于cookie+session的鉴权机制
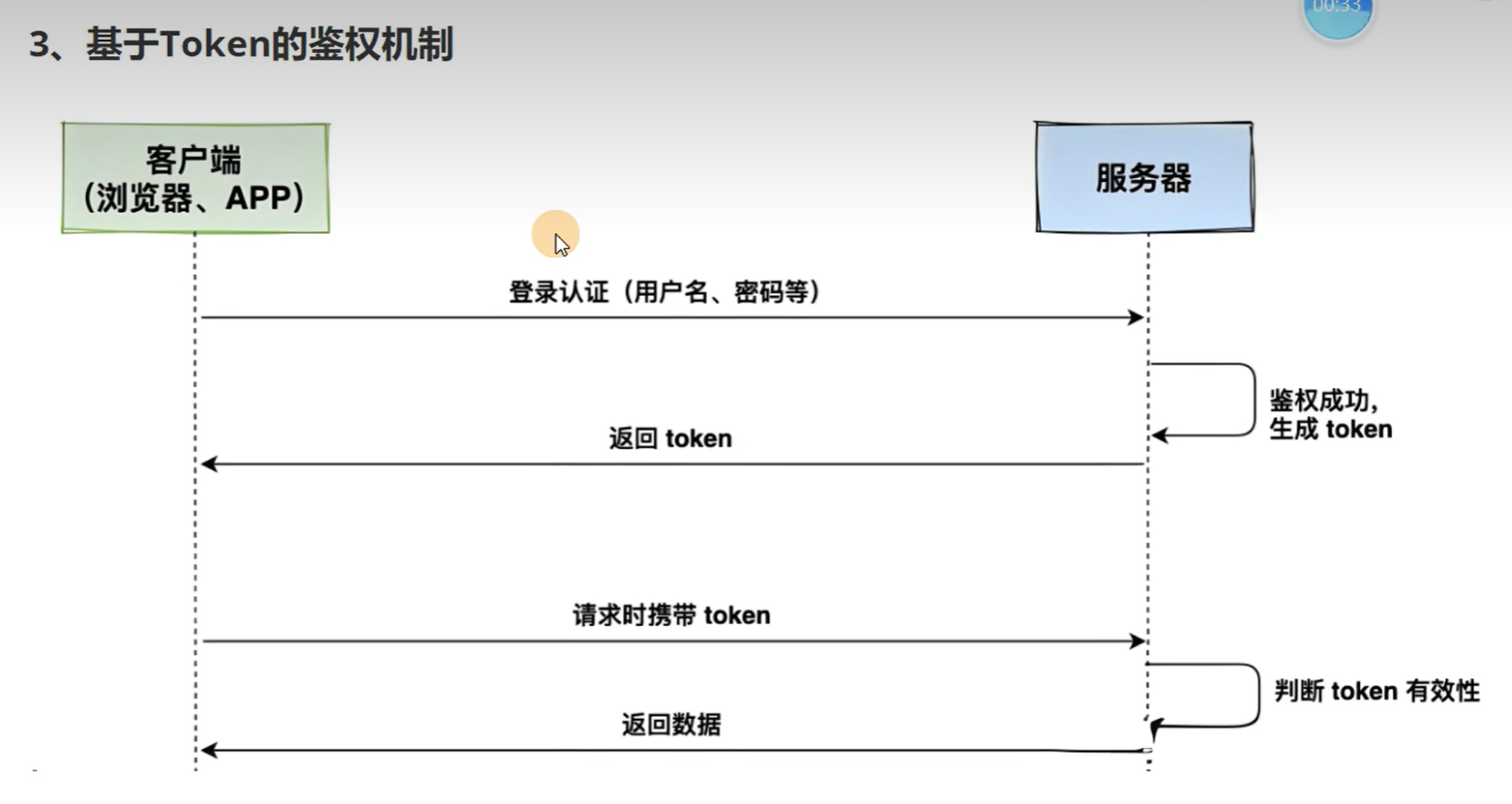
基于Token的鉴权机制
如何初步判断是采用的哪种鉴权?
form-data大概率是cookie+session
网站首页地址与登陆请求地址不一致,大概率是token鉴权
模拟登录中华网 模拟登录、访问需要登录之后才能够访问的页面
1发送登录请求
保存cookie信息
下次请求需要登录页面直接携带cookie信息
1 2 3 中华网账号 https://passport.china.com/ username:17775990925 password:a546245426
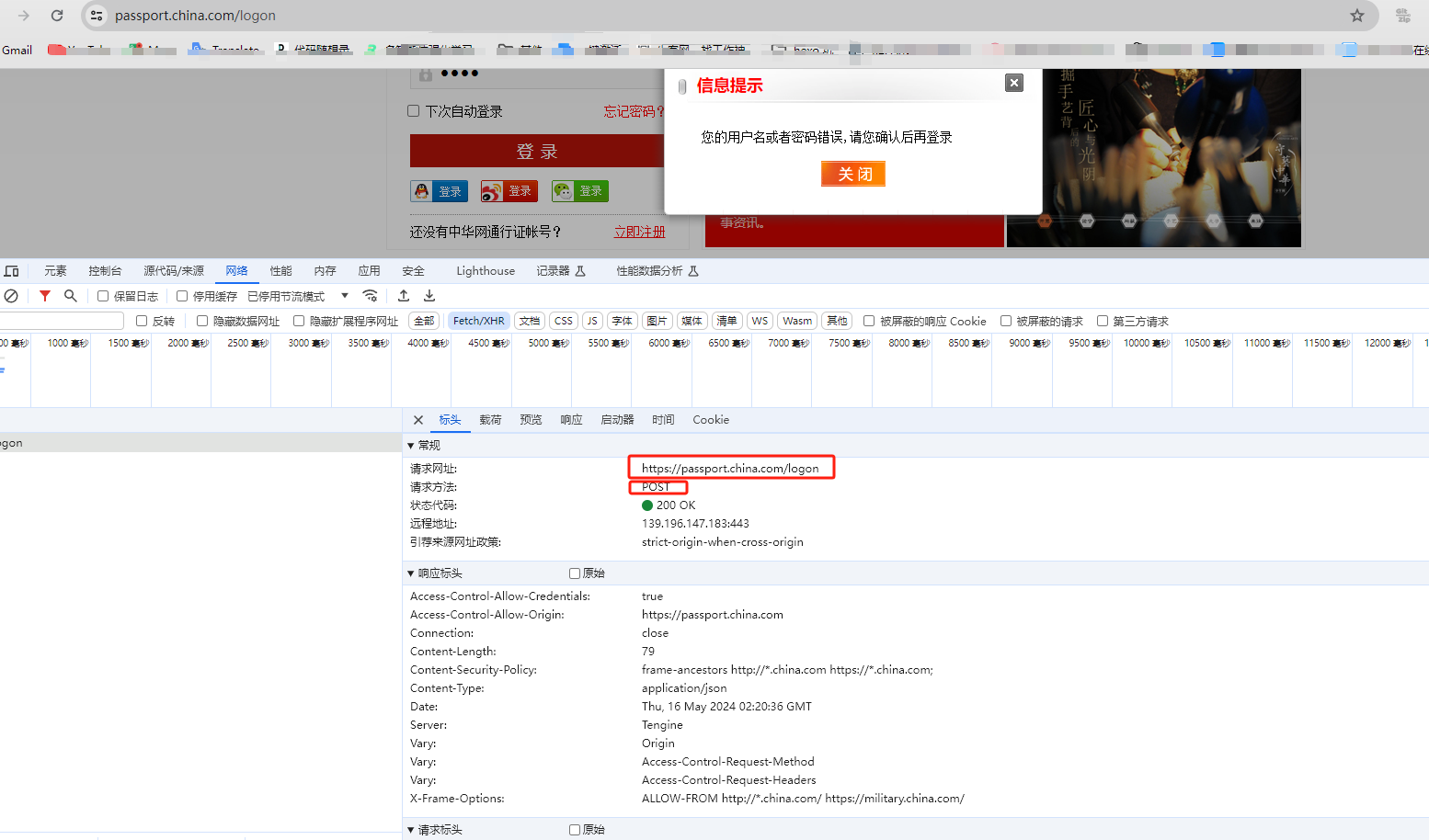
通过抓包找到登录接口地址,注意这里用错误的账号或者密码,如果是正确的则会自动跳转,无法找出登录接口
利用python构造请求模拟登录实例
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 import requestsurl = "https://passport.china.com/logon" headers = { "User-Agent" : "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/104.0.0.0 Safari/537.36" , "Referer" : "https://passport.china.com/logon" , } params={ "userName" : "17775990925" , "password" : "a546245426" } """ 如何提取请求的cookie信息: response.cookies 如何解决利用cookie进行校验的访问请求: 方式一: request.get(cookies=cookies),利用参数让请求携带cookie信息,cookie字典格式 方式二: 请求头中携带,cookie以字符串格式 headers={ "Cookie":cookie值 } 方式三:requests.session 利用: requests.session()对象去发送请求,其会自动记住状态信息 """ login_url = "https://passport.china.com/logon" main_url = "https://passport.china.com" session = requests.session() session.post(login_url,data=params,headers=headers) response = session.get(main_url,headers=headers) print (response.content.decode())
Ajax异步数据 背景:大对数网站采用前后端分离方式构建应用,数据都是通过Ajax请求异步加载获取的,直接请求目标网站的话,返回的内容中压根就没有任何数据
比如对于东方财富:https://quote.eastmoney.com/center
浏览器抓包分析,发现页面数据根本不在请求返回的html文件中,他的数据都是通过异步请求得到的
对于这类型的网站,抓取数据的地址根本不是页面上的地址,因为html中压根就没有数据,我们要去分析其发送的AJAX请求,获取对应的URL,然后去抓取对应的数据
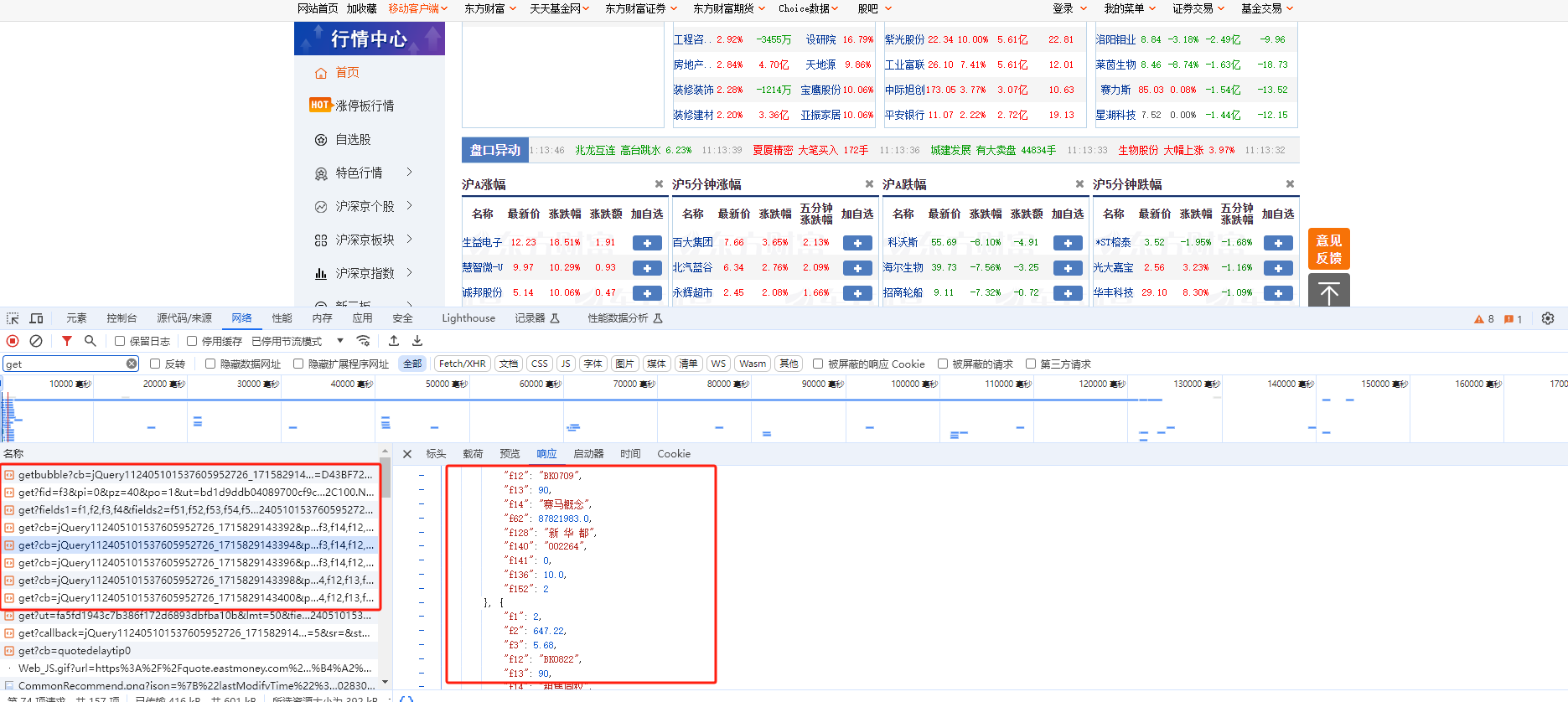
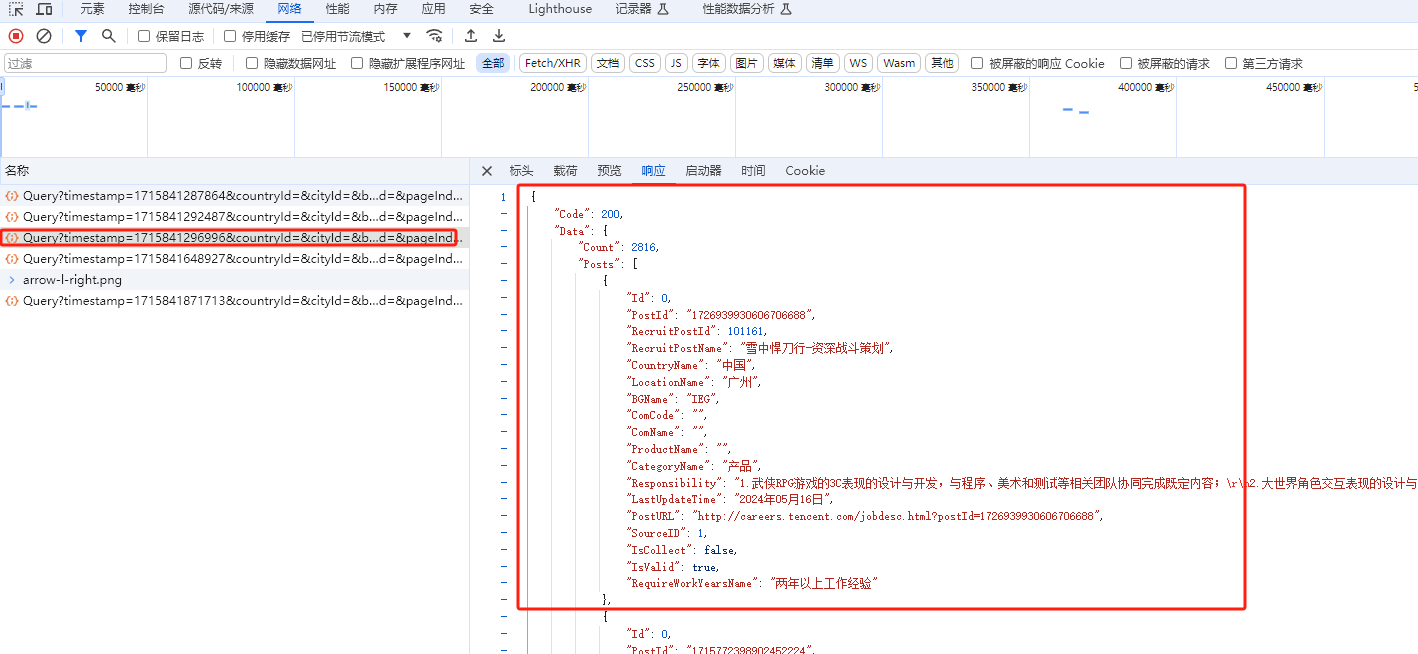
异步数据抓取案例 我们选取腾讯招聘 网站作为爬取目标,我们可以发现它的网站职位数据就是异步加载的
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 """ url:https://careers.tencent.com/tencentcareer/api/post/Query 请求参数: timestamp: 1715841296996 countryId: cityId: bgIds: productId: categoryId: parentCategoryId: attrId: keyword: pageIndex: 1 pageSize: 10 language: zh-cn area: cn """ import requestsimport timebase_url = "https://careers.tencent.com/tencentcareer/api/post/Query" params={ "timestamp" : 1715841296996 , "countryId" :"" , "cityId" :"" , "bgIds" :"" , "productId" :"" , "categoryId" :"" , "parentCategoryId" :"" , "attrId" :"" , "keyword" :"" , "pageIndex" : 1 , "pageSize" : 10 , "language" : "zh-cn" , "area" : "cn" } """ 可变的参数: pageIndex以及timestamp """ for pageIndex in range (1 ,1000 ): params["timestamp" ] = int (time.time()*1000 ) params["pageIndex" ] = pageIndex print ("=" *10 ,"current pageInde:{}" .format (pageIndex),"=" *10 ) response = requests.get(url=base_url,params=params) result_data = response.json() job_count = result_data["Data" ]["Count" ] if job_count==0 : break job_list = result_data["Data" ]["Posts" ] for job in job_list: print (job["RecruitPostName" ])
数据格式转换问题 有些网站,我们抓取时,响应返回的数据形式比较复杂,我们如何从中快速提取想要的数据
对于非结构化数据:HTML
对于结构化数据:json、xml等
json模块 json.loads
把json格式字符串解码转换成python对象,json数组对应列表、json对象对应字典
python中的None,在json中用null表示
json.dumps
实现把python类型转换为json字符串,返回一个str对象,是把python对象编码成json字符串
其序列化默认采用ascii编码
添加参数 ensure_ascii=False禁用ascii编码,按utf-8编码
python json转换参考资料
jsonPath 正如XPath之于XML文档一样,JsonPath为Json文档提供了解析能力,通过使用JsonPath,你可以方便的查找节点、获取想要的数据,JsonPath是Json版的XPath
其用法基本跟xpath一致
参考资料
python jsonpath教程
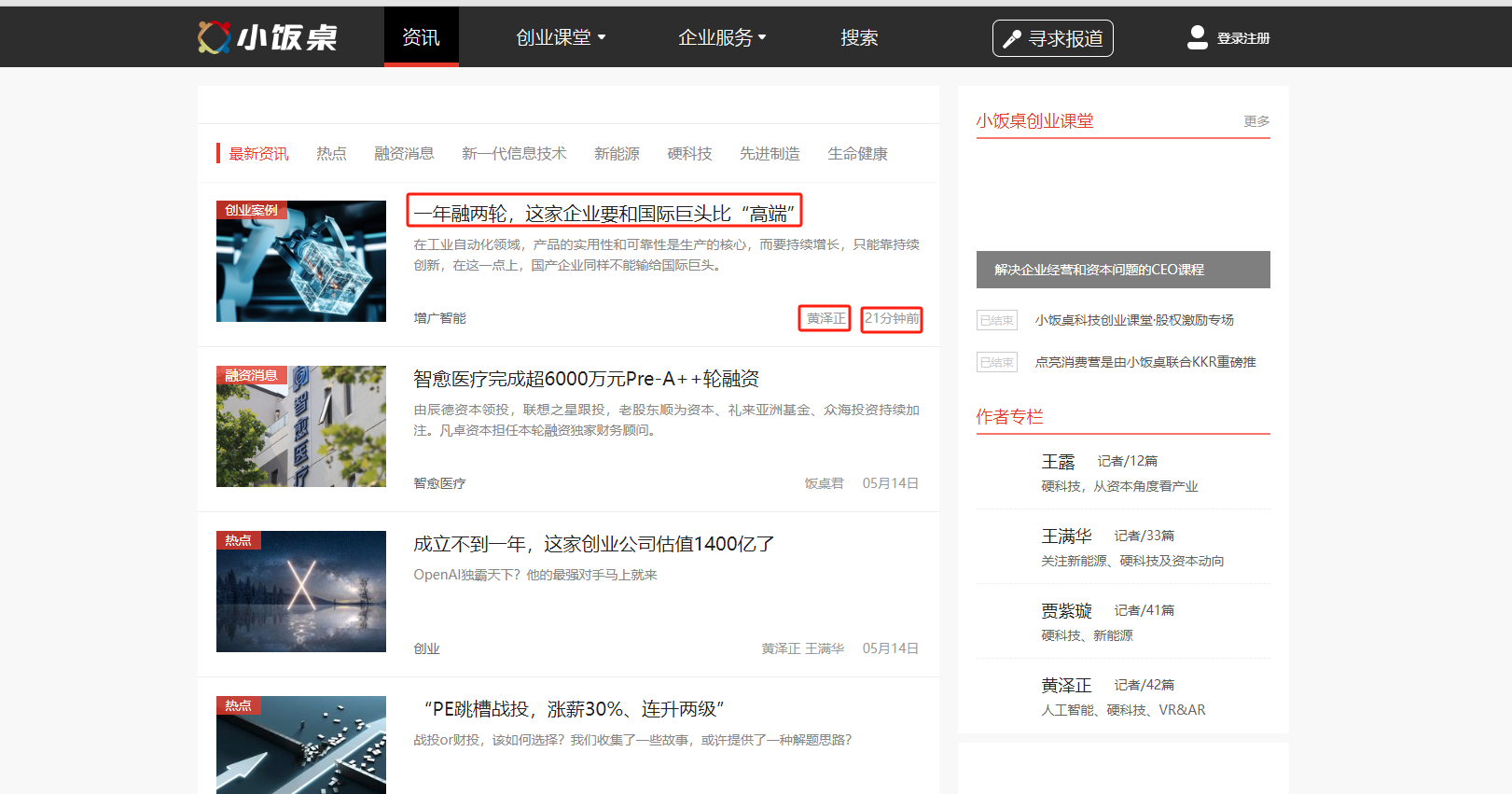
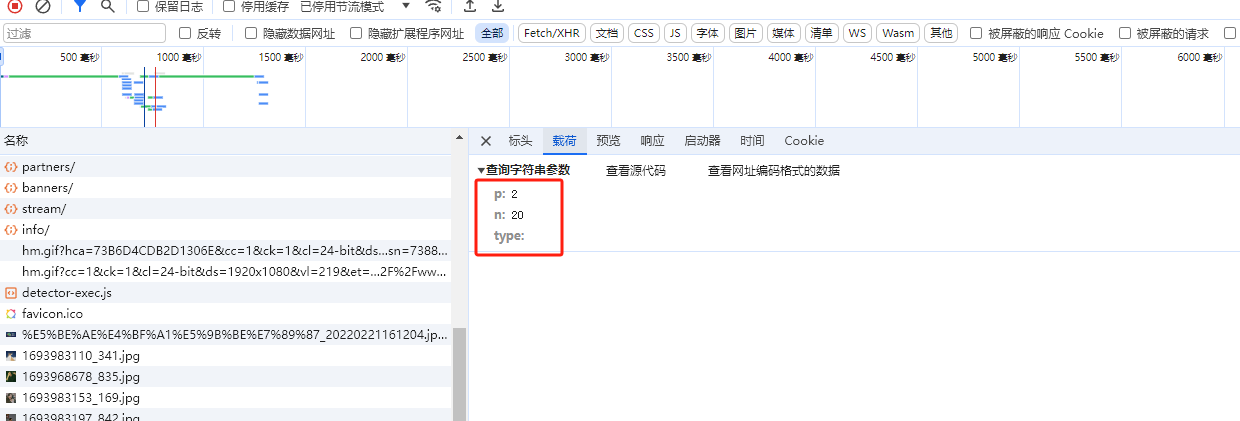
案例:jsonpath进行数据提取 目标网站小饭桌 ,我们提取各个咨询的标题、发布作者、发布事件信息
其响应数据格式如下图所示:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 { "uid" : 10918 , "title" : "智愈医疗完成超6000万元Pre-A++轮融资" , "photo" : "https://static-image.xfz.cn/1715658195_783.jpg" , "author" : { "photo" : "https://static-image.xfz.cn/1552965456_492.jpg" , "authors" : [ { "author_id" : 500 , "name" : "饭桌君" } ] } , "is_original" : false , "article_type" : "融资消息" , "intro" : "由辰德资本领投,联想之星跟投,老股东顺为资本、礼来亚洲基金、众海投资持续加注。凡卓资本担任本轮融资独家财务顾问。" , "source" : "" , "time" : "2024-05-14 11:43:15" , "keywords" : [ "智愈医疗" ] }
我们需要从中解析出我们想要的数据
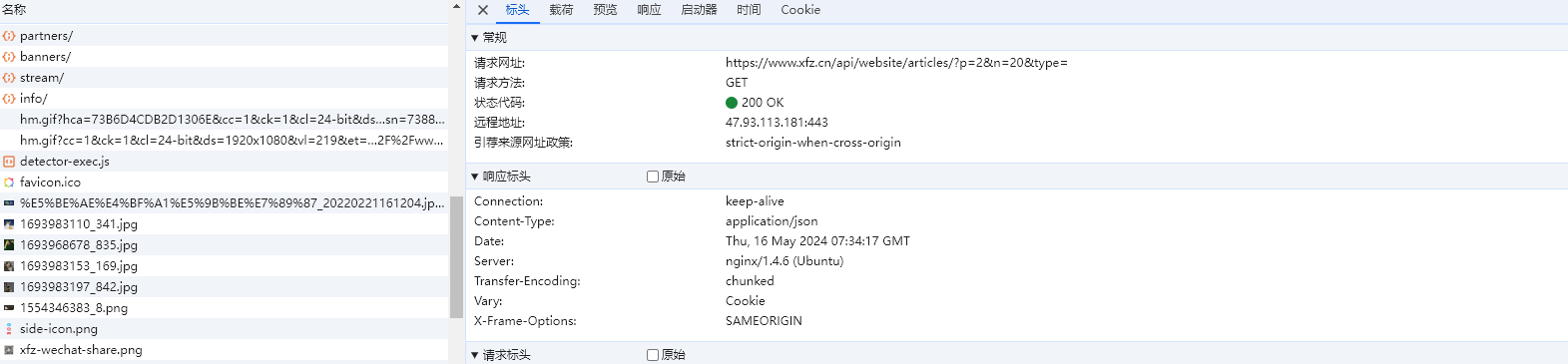
我们首先抓包,分析其数据异步加载的接口以及对应的请求参数,分析不同分页url和请求参数的规律
其请求的数据
python代码
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 """ { "uid": 10874, "title": "与微软合作,这家独角兽让GPT对中国企业开放了", "photo": "https://static-image.xfz.cn/1708917564_964.jpg", "author": { "photo": "https://static-image.xfz.cn/1693983197_842.jpg", "authors": [ { "author_id": 2295, "name": "黄泽正" } ] }, "is_original": true, "article_type": "热点", "intro": "中国企业合法合规使用GPT的时代,终于来了。", "source": "", "time": "2024-02-26 11:19:24", "keywords": [ "GPT", "易点云", "IT综合解決方案供应商" ] } """ import requestsimport jsonpathimport jsonbase_url = "https://www.xfz.cn/api/website/articles/" params={ "p" : 2 , "n" : 20 , "type" :"" } for p in range (1 ,100 ): params["p" ]=p response = requests.get(url=base_url,params=params) response_json = response.json() title_list = jsonpath.jsonpath(response_json,"$..title" ) author_list = jsonpath.jsonpath(response_json,"$..author..name" ) time_list = jsonpath.jsonpath(response_json,"$..time" ) for title,author,time in zip (title_list,author_list,time_list): print (title,"\t" ,author,"\t" ,time)
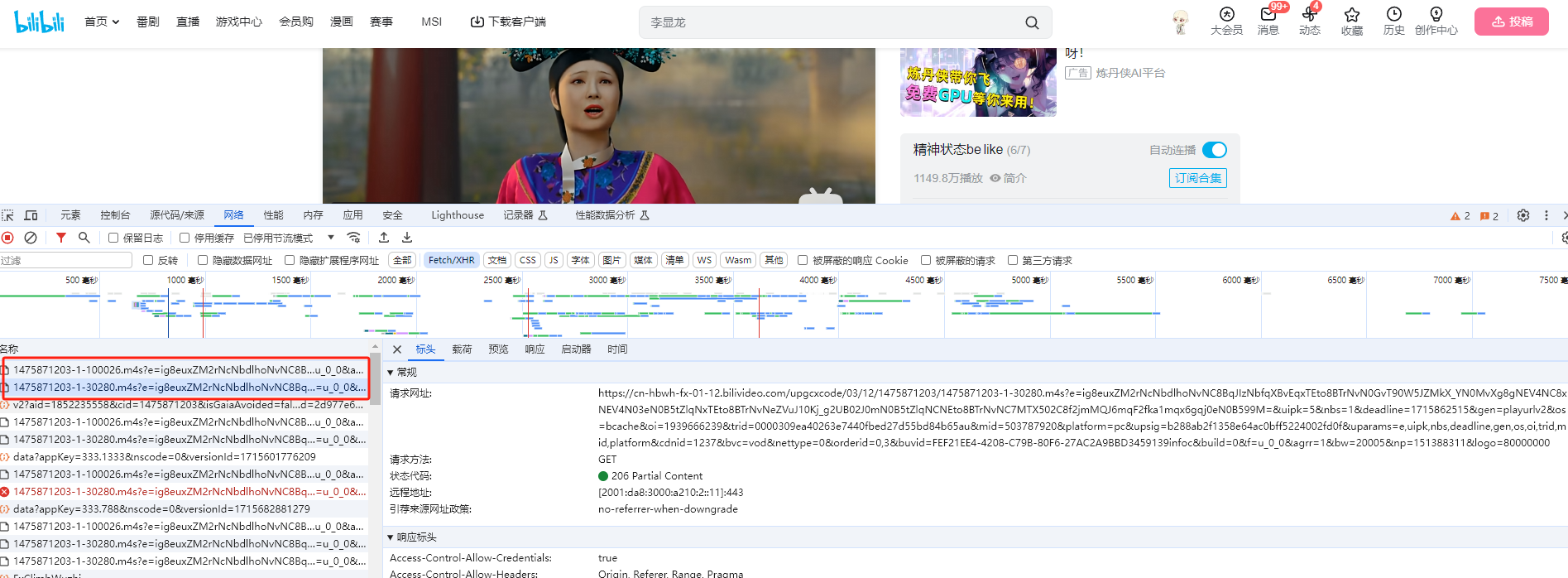
视频抓取 B站视频抓取 资源抓取 B站视频的画面和音频是通过不同的url来异步请求获取,所以我们抓包分析得到画面和音频的请求链接,然后分别抓取画面和音频,最后在本地将两者合成视频文件
抓包分析,最开始的两个请求即为画面和音频资源请求
视频合成 MoviePy是一个用于视频编辑的Python模块,它可以用于一些基本操作,比如剪切、拼接、插入标题、视频合成、视频处理和创建高级特效
官网教程
参考博客
代码示例: 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 """ 分析: 对于B站而言,其视频和音频内容是分开请求的,最终的视频是由两者一起合成的 """ import requests""" 注意:经过验证,如果不携带User-Agent和Referer这两个请求头,会直接返回403 forbidden """ headers = { "User-Agent" : "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/104.0.0.0 Safari/537.36" , "Referer" :"https://www.bilibili.com/video/BV1Mp421m7Ck/?spm_id_from=333.1007.tianma.1-1-1.click&vd_source=91a99cf2cdc8a7bec61c79b14c7a9800" } url1="https://cn-hbwh-fx-01-13.bilivideo.com/upgcxcode/03/12/1475871203/1475871203-1-100026.m4s?e=ig8euxZM2rNcNbdlhoNvNC8BqJIzNbfqXBvEqxTEto8BTrNvN0GvT90W5JZMkX_YN0MvXg8gNEV4NC8xNEV4N03eN0B5tZlqNxTEto8BTrNvNeZVuJ10Kj_g2UB02J0mN0B5tZlqNCNEto8BTrNvNC7MTX502C8f2jmMQJ6mqF2fka1mqx6gqj0eN0B599M=&uipk=5&nbs=1&deadline=1715855097&gen=playurlv2&os=bcache&oi=1939666239&trid=00002988359d2ffb4c87ad295bbe92858e17u&mid=503787920&platform=pc&upsig=9252145cbb94964367b3213d88a75b0f&uparams=e,uipk,nbs,deadline,gen,os,oi,trid,mid,platform&cdnid=3881&bvc=vod&nettype=0&orderid=0,3&buvid=FEF21EE4-4208-C79B-80F6-27AC2A9BBD3459139infoc&build=0&f=u_0_0&agrr=1&bw=173938&np=151388311&logo=80000000" url2="https://cn-hbwh-fx-01-12.bilivideo.com/upgcxcode/03/12/1475871203/1475871203-1-30280.m4s?e=ig8euxZM2rNcNbdlhoNvNC8BqJIzNbfqXBvEqxTEto8BTrNvN0GvT90W5JZMkX_YN0MvXg8gNEV4NC8xNEV4N03eN0B5tZlqNxTEto8BTrNvNeZVuJ10Kj_g2UB02J0mN0B5tZlqNCNEto8BTrNvNC7MTX502C8f2jmMQJ6mqF2fka1mqx6gqj0eN0B599M=&uipk=5&nbs=1&deadline=1715855097&gen=playurlv2&os=bcache&oi=1939666239&trid=00002988359d2ffb4c87ad295bbe92858e17u&mid=503787920&platform=pc&upsig=1d8cc071b206465e33d41d8e298308d9&uparams=e,uipk,nbs,deadline,gen,os,oi,trid,mid,platform&cdnid=1237&bvc=vod&nettype=0&orderid=0,3&buvid=FEF21EE4-4208-C79B-80F6-27AC2A9BBD3459139infoc&build=0&f=u_0_0&agrr=1&bw=20005&np=151388311&logo=80000000" response1 = requests.get(url1,headers=headers) response2 = requests.get(url2,headers=headers) with open ("b站1.mp4" ,"wb" ) as f: f.write(response1.content) with open ("b站2.mp4" ,"wb" ) as f: f.write(response2.content) from moviepy.editor import ffmpeg_toolsffmpeg_tools.ffmpeg_merge_video_audio("b站1.mp4" ,"b站2.mp4" ,"b站.mp4" )
抖音视频抓取 我们抓包分析,抖音各个视频的链接都是杂乱无规则的,所以无法用requests批量抓取,如果要批量抓取,只能模拟人来不断点击获取,这个就必须要用到自动化工具selenium了
对于单个视频的下载比较简单,无任何其他的限制,直接发送请求即可获取
1 2 3 4 5 6 7 8 import requestsurl="https://v3-weba.douyinvod.com/02263c98b4f10164f58047cc60b11827/6645f1ed/video/tos/cn/tos-cn-ve-15/osB7nDAWI4MQuoB8ECDoeGezOhEs4BbeV2AqM1/?a=6383&ch=5&cr=3&dr=0&lr=all&cd=0%7C0%7C0%7C3&cv=1&br=1199&bt=1199&cs=0&ds=3&ft=kmz2Nvx2llUpoDtWsRdusEBOG4kbZ0Fl~z7avjZmpmPt188HKw9gHlcApW9w6x&mime_type=video_mp4&qs=0&rc=aDk6Omc7ZjY7OTszN2c7Z0BpM3hnNGQ6Zmd4czMzNGkzM0BiLmBiXjZgX14xX2I0NTQ1YSMvYm1ycjRfMy5gLS1kLTBzcw%3D%3D&btag=c0000e00030000&cquery=101s_100B_100x_100z_100a&dy_q=1715855997&feature_id=f0150a16a324336cda5d6dd0b69ed299&l=20240516183955A37ACE947DDB97002DEE" response = requests.get(url) with open ("抖音.mp4" ,"wb" ) as f: f.write(response.content)
单个视频url无任何规律,所以无法通过代码去批量构造,批量爬取的核心就在于如何批量获取视频的url列表
selenium的使用 selenium 是一个Web的自动化测试工具,最初是为了网站自动化测试而开发的,其可以按照指定的指令自动操作,其可以直接运行在浏览器之上,它支持所有主流的浏览器,模拟人去手动操作浏览器
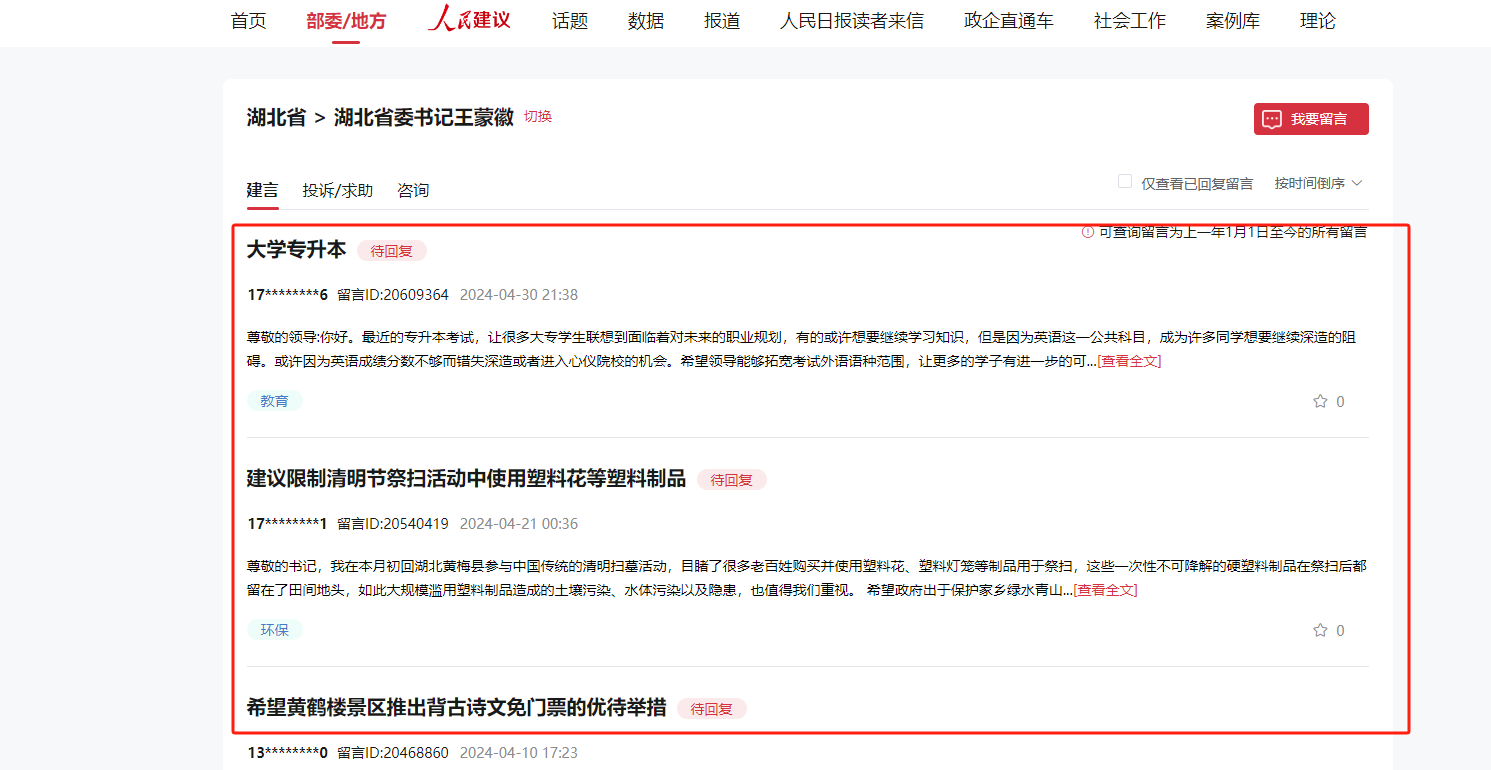
背景 我们以领导留言板 这个网站为例,抓取里面的内容,通过抓包获取url,请求参数以及请求等信息,但还是会被拦截
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 import requestsurl = "https://liuyan.people.com.cn/v1/threads/list/df" params={ "appCode" : "PC42ce3bfa4980a9" , "token" : "" , "signature" : "315b4bdafbf17b3dbb6a48a244b67dff" , "param" : "{\"fid\":\"571\",\"showUnAnswer\":1,\"typeId\":5,\"lastItem\":\"\",\"position\":\"0\",\"rows\":10,\"orderType\":2}" } headers = { "User-Agent" : "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/104.0.0.0 Safari/537.36" , "Referer" : """https://liuyan.people.com.cn/threads/list?checkStatus=0&fid=571&formName=%E6%B9%96%E5%8C%97%E7%9C%81%E5%A7%94%E4%B9%A6%E8%AE%B0%E7%8E%8B%E8%92%99%E5%BE%BD&position=0&province=28&city=&saveLocation=28&pForumNames=%E6%B9%96%E5%8C%97%E7%9C%81""" ,"Cookie" :"__jsluid_s=4b575e53f2419a15d98413b3c2ade788; Hm_lvt_40ee6cb2aa47857d8ece9594220140f1=1715856547; language=zh-CN; deviceId=52e3892d-030a-4de8-8d77-c62c7c0a1a87; Hm_lpvt_40ee6cb2aa47857d8ece9594220140f1=1715856654" } response = requests.get(url=url,headers=headers,data=params) print (response.content.decode())
响应内容:
其网站内部设置了防护和反扒机制,单纯靠requests是无法处理的,所以这是我们就需要借助于Selenium,模拟人类登录网站的行为,来进行数据的抓取
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 C:\environment \anaconda 3\envs \scrap \python .exe "C:\bang \MyOwn \Java 重要知识点学习\BaiduSyncdisk \0 7 python网络爬虫\my _ code\ch 04-selenium\领 导留言板.py" <!DOCTYPE html> <html> <head> <meta charset="utf-8" /> <style> body{ background:# eff1f0; font-family: microsoft yahei; color:#9 69696; font-size:12px;} .online-desc-con { text-align:center; } .r-tip01 { color: #9 69696; font-size: 16px; display: block; text-align: center; width: 600px; padding: 0 10px; overflow: hidden; text-overflow: ellipsis; margin: 0 auto 15px; } .r-tip02 { color: # b1b0b0; font-size: 12px; display: block; margin-top: 20px; margin-bottom: 20px; } .r-tip02 a:visited { text-decoration: underline; color: #0 088CC; } .r-tip02 a:link { text-decoration: underline; color: #0 088CC; } img { border: 0; } </style> </head> <body> <div class="online-desc-con" style="width:650px;padding-top:15px;margin:34px auto;"> <a id="official_ site" href="http://www.365cyd.com" target="_ blank"> <img id="wafblock" alt="" style="margin: 0 auto 17px auto;" /> </a> <span class="r-tip01" id="error_ 403"></span> <span class="r-tip01" id="error_ 403_ en"></span> <span class="r-tip02">如果您是网站管理员<a href="http://help.365cyd.com/cyd-error-help.html?code=403" target="_ blank">点击这里</a>查看详情</span> <hr/> <center>client: <span id="client_ ip"></span>, server: e85ed68, time: <span id="time_ error"></span><span id="rule_ id"></span></center> <img alt="" src="/cdn-cgi/image/logo.png" /> </div> <script> void(function fuckie6(){if(location.hash & & /MSIE 6/.test(navigator.userAgent) & & !/jsl_ sec/.test(location.href)){location.href = location.href.split('# ')[0] + '& jsl_ sec' + location.hash}})(); var data = {"error_ 403_ type":"cli_ ip","error_ 403":"您的IP( 218.106.117.241 )最近有可疑的攻击行为,请稍后重试.","client_ ip":"218.106.117.241","time_ error":"16\/ May\/ 2024:19:01:37 +0800","error_ 403_ en":""}; var rule_ id = parseInt(data['rule_ id']) || ''; if (rule_ id != '') { rule_ id = '[' + rule_ id + ']'; } document.getElementById("wafblock").src = '/cdn-cgi/image/' + (data['error_ 403_ type'] || 'hacker') + '.png'; document.getElementById('error_ 403').innerText = data['error_ 403'] || '当前访问疑似黑客攻击,已被创宇盾拦截。'; document.getElementById('error_ 403_ en').innerText = data['error_ 403_ en']; document.getElementById('client_ ip').innerText = data['client_ ip']; document.getElementById('time_ error').innerText = data['time_ error']; document.getElementById('rule_ id').innerText = rule_ id; </script> </body> </html> Process finished with exit code 0
使用Selenium的一般流程
selenium打开浏览器
访问要爬取的页面,如果有需要可以设置对页面进行一些操作
获取想要爬取的页面数据
selenium环境安装 selenium安装
浏览器对应的驱动chromedriver的下载
chromeDriver下载参考资料
chromeDriver参考资料
ChromeDriver下载地址列表
安装之后可以在代码中指定charomeDriver的地址或者我们可以直接将chromeDriver放在python的安装文件夹中,更推荐后者
测试是否安装成功:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 from selenium import webdriverimport requestsimport timeurl="https://www.baidu.com" driver = webdriver.Chrome() driver.get(url) time.sleep(1 ) html = driver.page_source print (html)driver.quit()
会自动弹出百度首页
selenium基本用法 Python selenium库官方文档
启动浏览器
1 2 from selenium import webdriverdriver = webdriver.Chrome()
访问页面
窗口最大化
1 driver.maximize_window()
刷新页面
获取页面源码
1 html = driver.page_source
页面截图
1 driver.save_screenshot("xxx.png" )
关闭浏览器
注意:
使用Selenium时,如果关闭的时候没有使用driver.quit退出,会导致系统中会启动多个chromeDriver程序,可以在命令行中通过如下命令批量删除chromedriver进程
1 taskkill /F /im chromedriver.exe
Selenium driver对象的相关属性
current_url:当前url地址
title:页面标题
page_source:页面html源码,注意这个页面源码与requests获取的源码是不一样的,其是所有js执行之后的完整的源码
window_handler:获取浏览器上所有窗口句柄,窗口句柄即各个窗口id
curren_window_handler:获取当前窗口的句柄
selenium元素定位和等待 元素定位的方法: selenium查找元素官网教程
一般我们知道如何通过xpath来定位元素就够了
案例:打开百度首页,在输入框中输入值进行搜索
首先打开百度首页,定位带搜索输入框元素,向输入框中输入值
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 import timefrom selenium import webdriverfrom selenium.webdriver.common.by import Bydriver = webdriver.Chrome() url = "https://www.baidu.com" driver.get(url) driver.maximize_window() element = driver.find_element(By.XPATH,'//*[@id="kw"]' ) element.send_keys("三国演义" ) time.sleep(3 ) driver.quit()
元素的属性和操作 元素属性
tagname:获取标签名
text:获取标签文本
parent:获取父级标签
get_attribute():获取属性
s_displayed():判断元素是否可见
元素的操作
click(),点击元素
send_keys():输入内容
clear():清空表单
selenium模拟登录案例 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 """ 需求分析: selenium模拟登录中华网:https://passport.china.com/logon """ from selenium import webdriverfrom selenium.webdriver.common.by import Byimport timeparams={ "userName" : "17775990925" , "password" : "a546245426" } driver = webdriver.Chrome() url = "https://passport.china.com/logon" driver.get(url) driver.maximize_window() userNameElement = driver.find_element(By.XPATH,'//*[@id="userInput"]/input[@name="userName"]' ) passWordElement = driver.find_element(By.XPATH,'//*[@id="55"]' ) loginButtonElement = driver.find_element(By.XPATH,'//*[@id="index_logonid"]' ) userNameElement.send_keys(params["userName" ]) passWordElement.send_keys(params["password" ]) loginButtonElement.click() time.sleep(5 ) driver.quit()
selenium爬取数据案例 需求分析
利用selenium爬取领导留言板数据
主要抓取各个留言的:
代码示例
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 """ selenium访问指定页面,并对页面解析,获取对应数据 """ from selenium import webdriverfrom selenium.webdriver.common.by import Byimport timefrom scrapy import selectorurl='https://liuyan.people.com.cn/threads/list?checkStatus=0&fid=571&formName=%E6%B9%96%E5%8C%97%E7%9C%81%E5%A7%94%E4%B9%A6%E8%AE%B0%E7%8E%8B%E8%92%99%E5%BE%BD&position=0&province=28&city=&saveLocation=28&pForumNames=%E6%B9%96%E5%8C%97%E7%9C%81' driver = webdriver.Chrome() driver.get(url) driver.maximize_window() time.sleep(5 ) titleElementList = driver.find_elements(By.XPATH,'//h1' ) textElementList = driver.find_elements(By.XPATH,'//p/span' ) timeElementList = driver.find_elements(By.XPATH,'//div[@class="headMainS fl"]/p' ) IdElementList = driver.find_elements(By.XPATH,'//span[contains(text(),"留言ID")]' ) for titleElement,timeElement,IdElement,textElemen in zip (titleElementList,timeElementList,IdElementList,textElementList): print (timeElement.text,"\t" ,titleElement.text,"\t" ,IdElement.text) print (textElemen.text) print ("=" *20 ) """ 页面元素分析,如何利用xpath进行解析: 标题: //h1/text() 正文: //p/span/text() 时间: //div[@class="headMainS fl"]/p/text() 留言ID://span[contains(text(),"留言ID")]/text() """ time.sleep(3 ) driver.quit()
目前存在的问题
selenium进阶使用 等待机制 官网 等待页面加载完成文档
背景 现在大多数网页都是动态加载的,如果页面内容发生变更,就需要时间来进行渲染,代码是自动执行的,有可能在执行的时候页面新的元素还没有加载出来,就查不到,报 no such element的错误,如果报这个错误,则有可能是定位表达式不正确,或者也可能是页面元素已经发生了变化
我们爬虫的过程中,如果打开新的页面、页面跳转等情况都要添加合适的等待,否则有的情况下会导致程序错误,无法进行下去
等待的三种方式
强制等待
隐式等待
driver.implicitly_wait(n)
显示等待(需要等待条件满足)
强制等待 time.sleep()
不管网页有没有加载完成,都会等待指定时间
隐式等待 driver.implicitly_wait(n)
如果某些元素不是立即可用的,隐式等待是告诉WebDriver去等待一定的时间后去查找元素。 默认等待时间是0秒
在n秒内如果还是找不到,则会抛出异常,在指定时间内,每隔一段时间就去看一下,如果成功找到,则程序会继续往下执行,如果没找到则继续等,直到最大等待时间
显示等待 可以设置等待条件,比如等待到某个元素可见、某个元素可点击
这种情况比较复杂,我们重点关注这种情况下如何使用
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 from selenium.webdriver.common.by import Byfrom selenium.webdriver.support.wait import WebDriverWaitfrom selenium.webdriver.support import expected_conditions as ECwait = WebDriverWait(driver, 10 ) located = (By.XPATH,"//input[@id='u'" ) conditions = EC.visibility_of_element_located(located) wait.until(conditions) WebDriverWait(driver, 10 ) .until(EC.visibility_of_element_located((By.XPATH,"//input[@id='u'" )))
常用显示等待条件
visibility_of_element_located:元素可见element_to_be_clickable:元素可点击
等待条件
presence_of_element_located:元素存在visibility_of_element_located:元素可见element_to_be_clickable:元素可点击title_contains:标题包含某内容new_window_is_opened:等待新窗口出现frame_to_be_available_and_switch_to_it:加载并切换到iframe中alert_is_present:出现Alert弹框
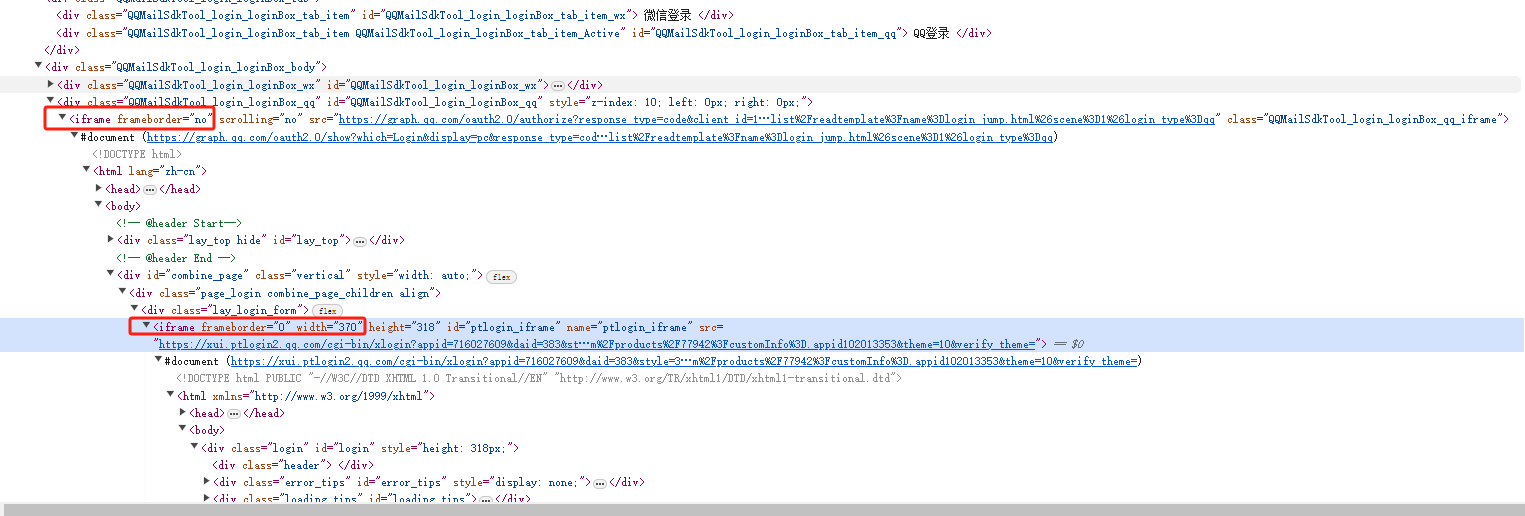
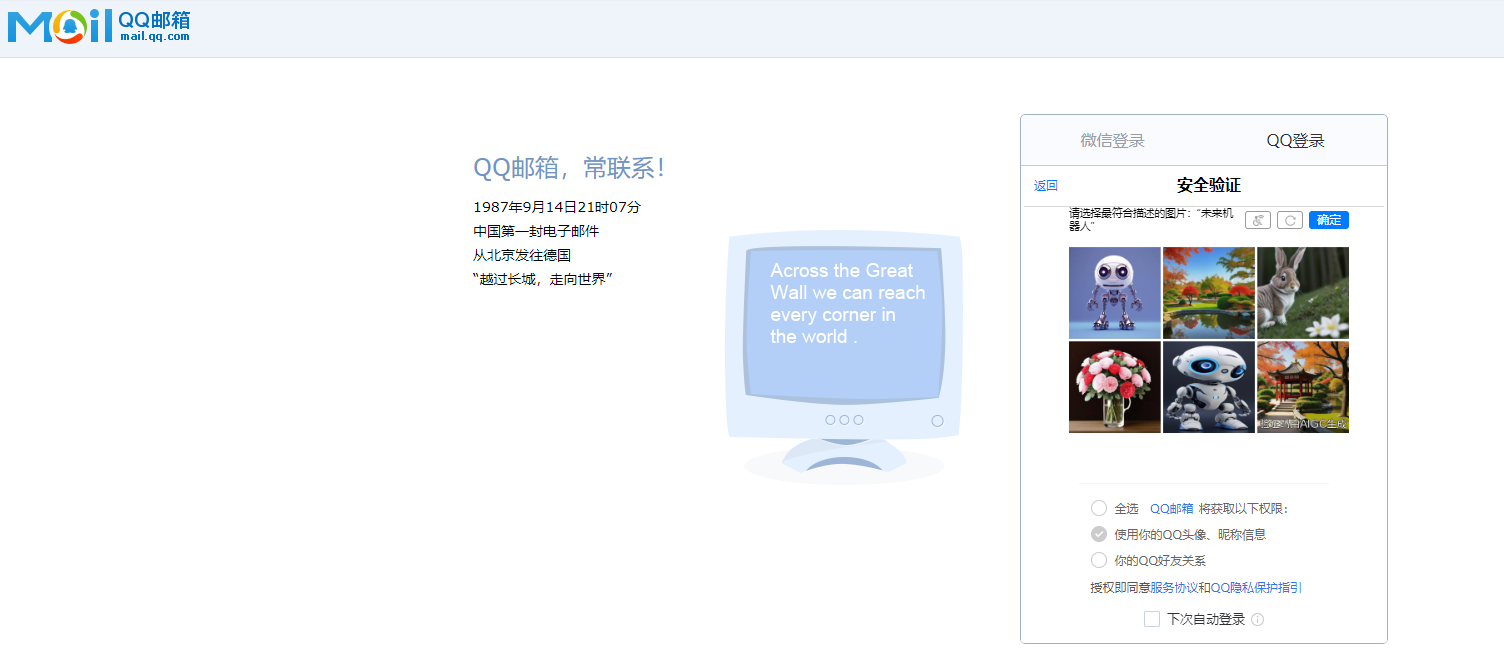
iframe切换 背景 对于QQ邮箱登录页面 ,其内部是一个网页嵌套另一个网页构成的,如果直接查找或者点击里面的某些元素是找不到的,必须要进行iframe切换
selenium控制iframe切换 1 2 3 4 5 6 7 8 9 10 11 12 13 driver.switch_to.frame('frame_name' ) iframeElement = driver.find_element_by_xpath('//iframe[@id="login_frame"]' ) driver.switch_to.frame(iframeElement) driver.switch_to.frame(1 ) driver.switch_to.default_content() driver.switch_to.parent_frame()
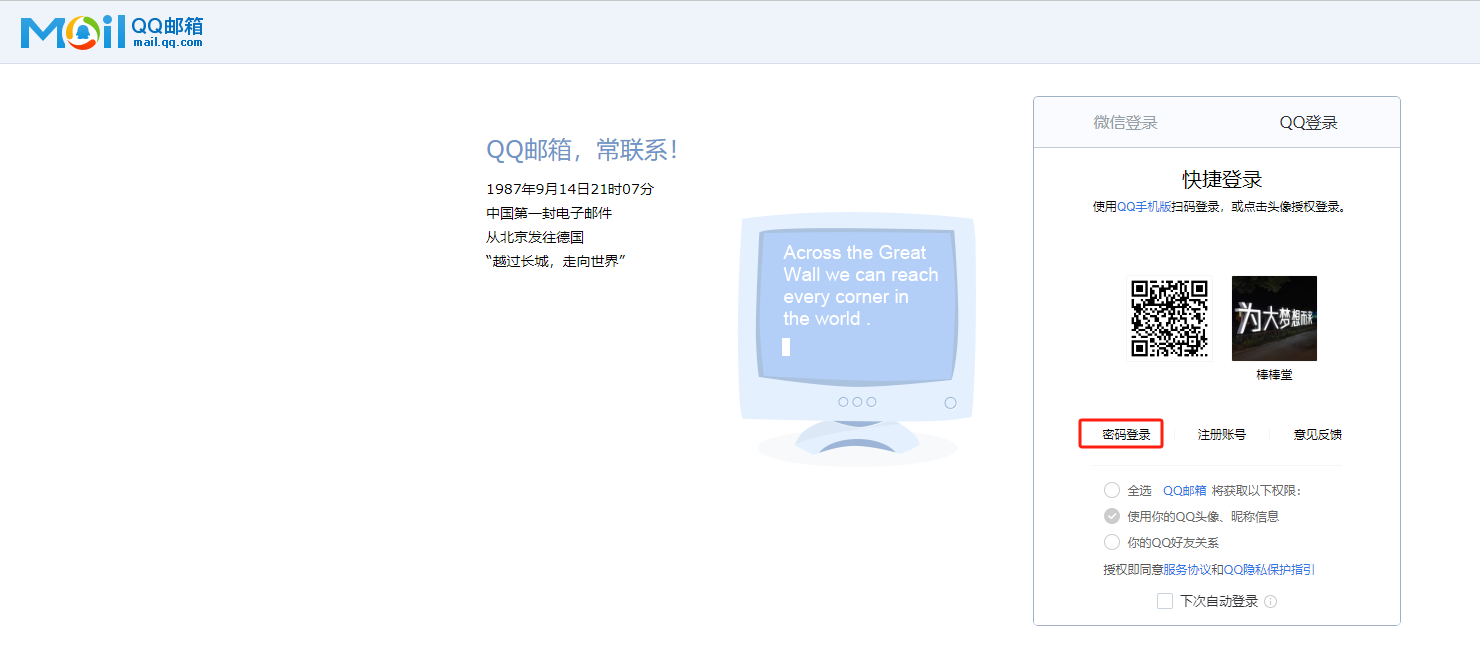
案例 模拟QQ邮箱登录页面点击密码登录,然后输入账号密码模拟登陆
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 from selenium import webdriverfrom selenium.webdriver.common.by import Byimport timedriver = webdriver.Chrome() url = "https://wx.mail.qq.com/" driver.get(url=url) driver.maximize_window() driver.switch_to.frame(1 ) iframeElement = driver.find_element(By.XPATH,'//iframe[@id="ptlogin_iframe"]' ) driver.switch_to.frame(iframeElement) passwordLoginButton = driver.find_element(By.XPATH,'//*[@id="switcher_plogin"]' ) passwordLoginButton.click() driver.find_element(By.XPATH,'//*[@id="u"]' ).send_keys("wujjjj" ) driver.find_element(By.XPATH,'//*[@id="p"]' ).send_keys("99899" ) time.sleep(1 ) driver.find_element(By.XPATH,'//*[@id="login_button"]' ).click() time.sleep(10 ) driver.quit()
执行结果
最终还会弹出
窗口滚动 背景 有的时候,元素虽然被加载出来了,但是如果看不到,是无法进行操作的,这时就需要滚动页面才会显示新的内容
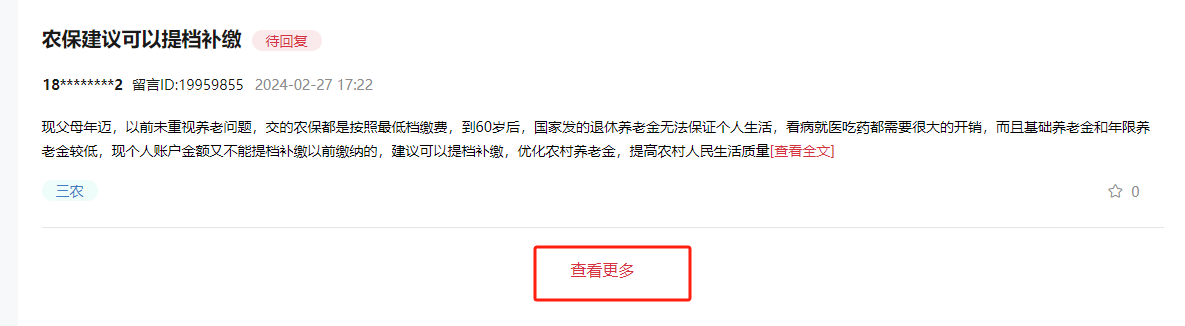
比如对于我们之前爬取的领导留言板 网站,就需要手动滚动页面到最底部,然后点击查看更多,才能分页查看下一页数据
所以要想抓取数据完全,需要不断查找查看更多按钮,然后点击进行翻页
代码示例 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 import timeimport randomfrom selenium import webdriverfrom selenium.webdriver.common.by import Byurl = "https://liuyan.people.com.cn/threads/list?checkStatus=0&fid=1179&formName=%E5%AE%9C%E6%98%8C%E5%B8%82%E5%A7%94%E4%B9%A6%E8%AE%B0%E7%86%8A%E5%BE%81%E5%AE%87&position=0&province=28&city=230&saveLocation=28&pForumNames=%E6%B9%96%E5%8C%97%E7%9C%81&pForumNames=%E5%AE%9C%E6%98%8C%E5%B8%82" driver = webdriver.Chrome() driver.implicitly_wait(10 ) driver.get(url) driver.maximize_window() while True : try : element = driver.find_element(By.XPATH, '//*[@class="mordList"]' ) print (element) time.sleep(random.randint(1 ,3 )) element.location_once_scrolled_into_view time.sleep(random.randint(1 ,3 )) element.click() except : break titleElementList = driver.find_elements(By.XPATH,'//h1' ) textElementList = driver.find_elements(By.XPATH,'//p/span' ) timeElementList = driver.find_elements(By.XPATH,'//div[@class="headMainS fl"]/p' ) IdElementList = driver.find_elements(By.XPATH,'//span[contains(text(),"留言ID")]' ) for titleElement,timeElement,IdElement,textElemen in zip (titleElementList,timeElementList,IdElementList,textElementList): print (timeElement.text,"\t" ,titleElement.text,"\t" ,IdElement.text) print (textElemen.text) print ("=" *20 ) print ("总条数:{}" .format (len (titleElementList)))time.sleep(5 ) driver.quit()
JS模拟滚动页面 js滚动窗口到指定坐标位置
scrollTo():可把内容滚动到指定的坐标
```js参数说明 x :必须,要在窗口文档显示区左上角显示的文档的x坐标1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 **selenium如何执行js代码** ```python #移动Y坐标到500的位置 js = "window.scrollTo(0,500)" driver.execute_script(js) #滚动到窗口底板 js = "window.scrollTo(0,document.body.scrollHeight)" driver.execute_script(js) #相对滚动 #scrollBy(x1,x2)表示相对当前位置(x,y),页面下一步滚动到 x+x1,y+y1 #有的时候,突然滚动到底部,可能会被反爬机制识别,这是用相对滑动,模拟人的操作 js = "window.scrollBy(0,100)" driver.execute_script(js)
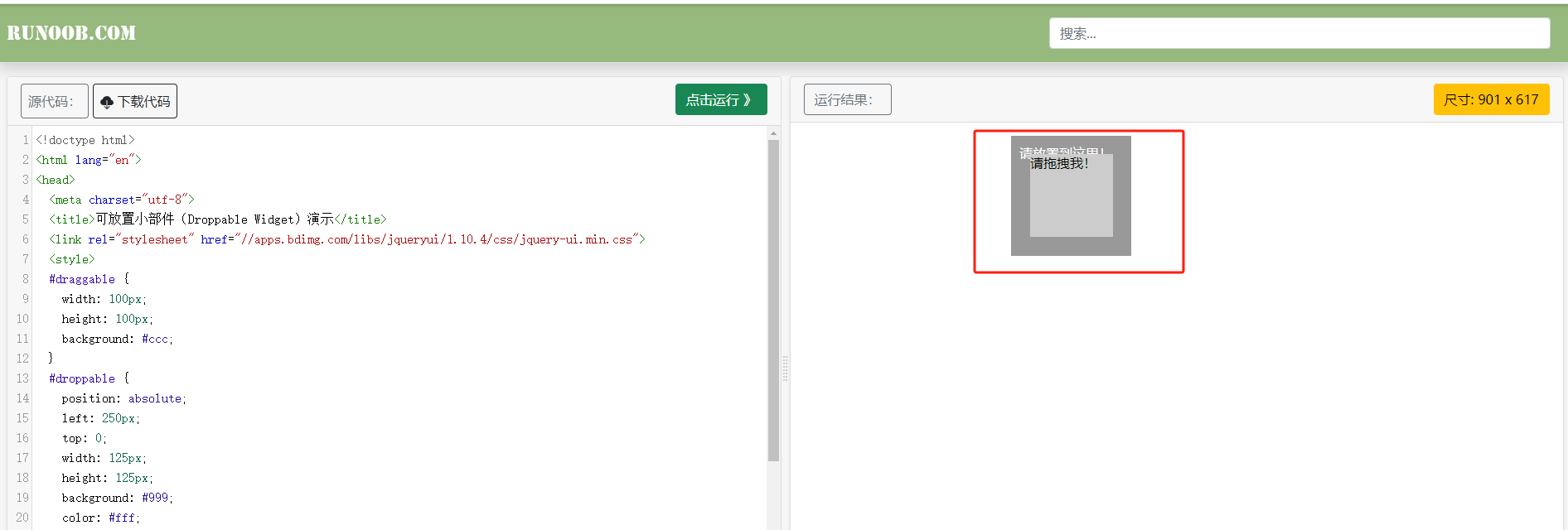
鼠标操作 比如:有的页面需要模拟鼠标操作,对页面元素进行拖拽操作,比如滑块验证码之类的
1 from selenium.webdriver import ActionChains
ActionChains:鼠标操作类
click:鼠标点击
double_click:鼠标双击
context_click:鼠标右击
move_to_element:鼠标移动到某个节点
click_and_hold:鼠标左键按下鼠标
move_by_offse:鼠标相对当前位置进行移动
drag_and_drop():在一个位置按下鼠标,到另一个位置进行释放
release:释放鼠标
perform:执行动作
鼠标操作练习网站
实例代码
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 from selenium.webdriver import ActionChainsfrom selenium import webdriverfrom selenium.webdriver.common.by import Byimport time""" ActionChains:鼠标操作类 - click:鼠标点击 - double_click:鼠标双击 - context_click:鼠标右击 - move_to_element:鼠标移动到某个节点 - click_and_hold:鼠标左键按下鼠标 - move_by_offse:鼠标相对当前位置进行移动 - drag_and_drop():在一个位置按下鼠标,到另一个位置进行释放 - release:释放鼠标 - perform:执行动作 """ driver = webdriver.Chrome() driver.implicitly_wait(10 ) driver.get('https://www.runoob.com/try/try.php?filename=jqueryui-api-droppable' ) driver.maximize_window() driver.switch_to.frame(driver.find_element(By.XPATH,'//*[@id="iframeResult"]' )) dragElement = driver.find_element(By.XPATH,'//*[@id="draggable"]' ) ac = ActionChains(driver) ac.move_to_element(dragElement) ac.click_and_hold() ac.move_to_element(driver.find_element(By.XPATH,'//*[@id="droppable"]' )) ac.perform() time.sleep(5 ) driver.quit()
执行结果
selenium携带cookie登录 很多网站需要登录才能访问其他页面,这种情况我们需要首先需要利用selenium模拟登录获取网站的cookie信息,然后在访问其他网站的时候模拟
参考资料
selenium特征检测 参考资料 js文件下载地址
selenium启动的浏览器可能具有以下特殊的特征
User-Agent字符串
Selenium启动的浏览器通常具有特定的User-Agent字符串,可以通过检查User-Agent来判断是否为Selenium启动的浏览器
自动化工具标识
Selenium启动的浏览器可能会在请求头中包含一些自动化工具的标识,例如Requested-With、DNT等
WebDriver相关属性
Selenium启动的浏览器可能会在全局window对象中注入一些特殊的属性,例如webdriver、navigator.webdriver等
页面加载行为
Selenium启动的浏览器通常会以自动化的方式加载页面,可能会出现一些快速点击、输入文本等行为
元素检测
Selenium启动浏览器的时候会在DOM中插入一些特定的元素或者属性,用于控制浏览器行为,可以通过检测这些特定的元素或属性来判断是否为Selenium启动的浏览器
如果想使用selenium正常访问,则需要在创建webdriver时隐藏浏览器相关的特征
--disable-infobars:禁止显示Chrome浏览器正在受到自动测试软件控制的通知栏excludeSwitches、enable-automation:排除启动自动化扩展程序的开关,可以防止被网站检测到使用了自动化测试工具,减少被反爬虫封锁的可能useAutomationExtension:False:禁用自动化扩展程序,同样为了避免被网站检测到使用了自动化工具通过Page.addScriptToEvaluateOnNewDocument方法,可以在每次页面加载时执行指定的JavaScript代码,我们每次打开新页面之前,执行hide.js来隐藏selenium启动浏览器生成的属性,从而防止被检测出来时爬虫
绕过特征检测案例 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 from selenium import webdriverimport time""" 目标网站: https://www.aqistudy.cn/ 对selenium做了反爬 如果用selenium打开,是不会有数据显示的 """ options = webdriver.ChromeOptions() options.add_argument("--disable-infobars" ) options.add_experimental_option("excludeSwitches" ,["enable-automation" ]) options.add_experimental_option("useAutomationExtension" ,False ) options.add_argument('user-agent=Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.198 Safari/537.36' ) driver = webdriver.Chrome(options=options) driver.implicitly_wait(10 ) with open ("../stealth.min.js" ) as f: js = f.read() driver.execute_cdp_cmd("Page.addScriptToEvaluateOnNewDocument" ,{ "source" : js }) url = 'https://www.aqistudy.cn/' driver.get(url) driver.maximize_window() time.sleep(20 ) driver.quit()
JS逆向分析 js参数加密案例 许多网站的请求参数都是加密传递的,要模拟发送请求,就得直到参数是怎么加密的,然后用代码实现加密的过程
比如对于一些网站的登录页面,其账号、密码传输时是通过某种加密算法加密后再发送请求的
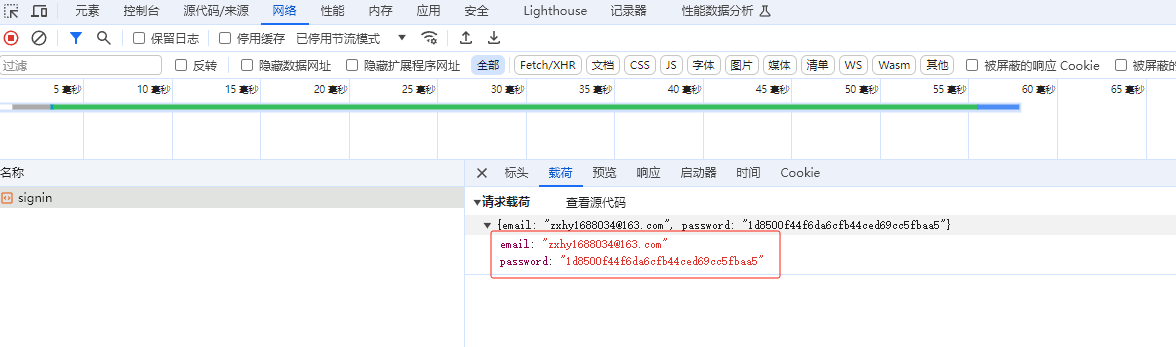
需求分析 对于 网站 的登录界面,
我们输入账号、密码模拟登录,抓包分析,发现其密码是加密后的数据
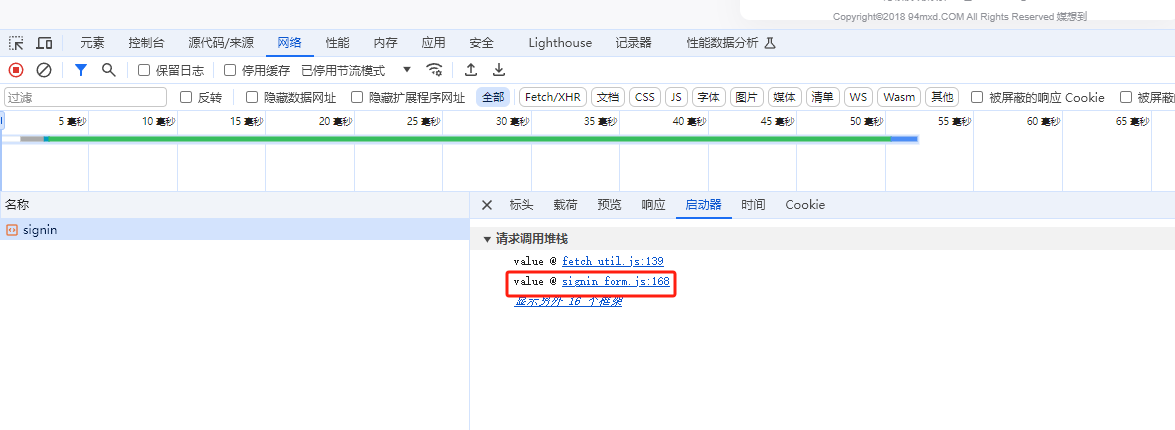
找到调用的js文件
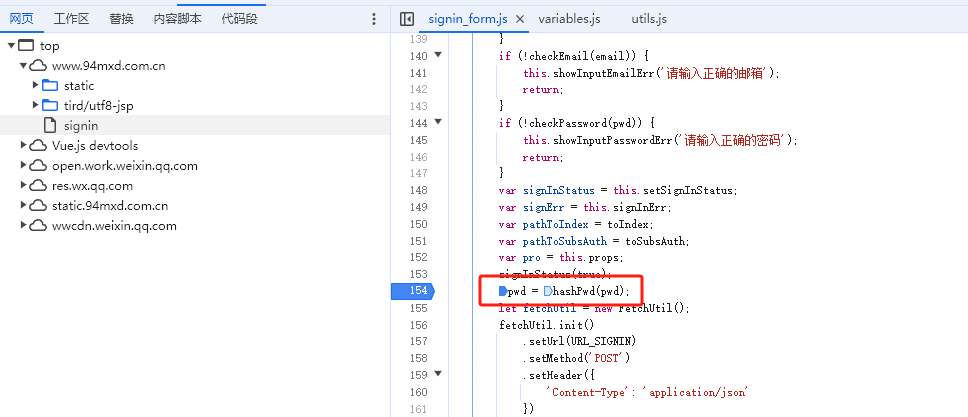
我们班通过打断点分析,定位带其js代码中加密的函数,实际上是一个 盐值拼接,然后采用md5加密得到
示例代码 1 2 3 4 5 6 7 8 9 10 11 12 import hashlibdef hashPwd (password ): saltValue = "Hq44cyp4mT9Fh5eNrZ67bjifidFhW%fb0ICjx#6gE59@P@Hr8%!WuYBa1yvytq$qh1FEM18qA8Hp9m3VLux9luIYpeYzA2l2W3Z" strVal = password+saltValue hashObj = hashlib.md5() hashObj.update(strVal.encode("utf-8" )) md5StrVal = hashObj.hexdigest() return md5StrVal
当然,如果我们采用selenium模拟登录,无需直到其加密算法,直接在输入框中输入明文,即可模拟登录
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 import timefrom selenium import webdriverfrom selenium.webdriver.common.by import Byurl = "https://www.94mxd.com.cn/signin" params={ "email" : "1985439923@qq.com" , "password" : "wu123456" } driver = webdriver.Chrome() driver.get(url) driver.maximize_window() driver.find_element(By.XPATH,'//*[@id="email"]' ).send_keys(params["email" ]) driver.find_element(By.XPATH,'//*[@id="password"]' ).send_keys(params["password" ]) time.sleep(1 ) driver.find_element(By.XPATH,'//*[@id="container"]/div/div/div[2]/div[2]//button' ).click() time.sleep(5 ) driver.quit()
调用js加密代码 在逆向分析时,有时候会发现某个js加密算法会比较繁琐,用python还原同样的算法会比较费劲,此时,我们可以不必使用python去还原,而是利用python去直接调用JavaScript中定义的功能,通过调式分析加密算法所在的位置和源码,然后直接在代码中调用该js代码
python调用js,需要借助于第三方库pyexcejs,这个库底层调用node.js,所以还需要安装node.js
代码示例
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 """ python调用js用第三方库: 需要安装python第三方库:pyexecjs 需要安装: node.js """ import execjsjsCode=""" function add(a,b){ return a+b } function say(){ return "say,hello!!!" } """ JS = execjs.compile (jsCode) result = JS.call("add" ,100 ,200 ) message = JS.call("say" ) print (result)print (message)
验证码破解 图像验证码破解 许多网站,在登陆的时候,除了输入账号、密码之外,还会显示一个图像验证码,那么这类网站应该如何破解?
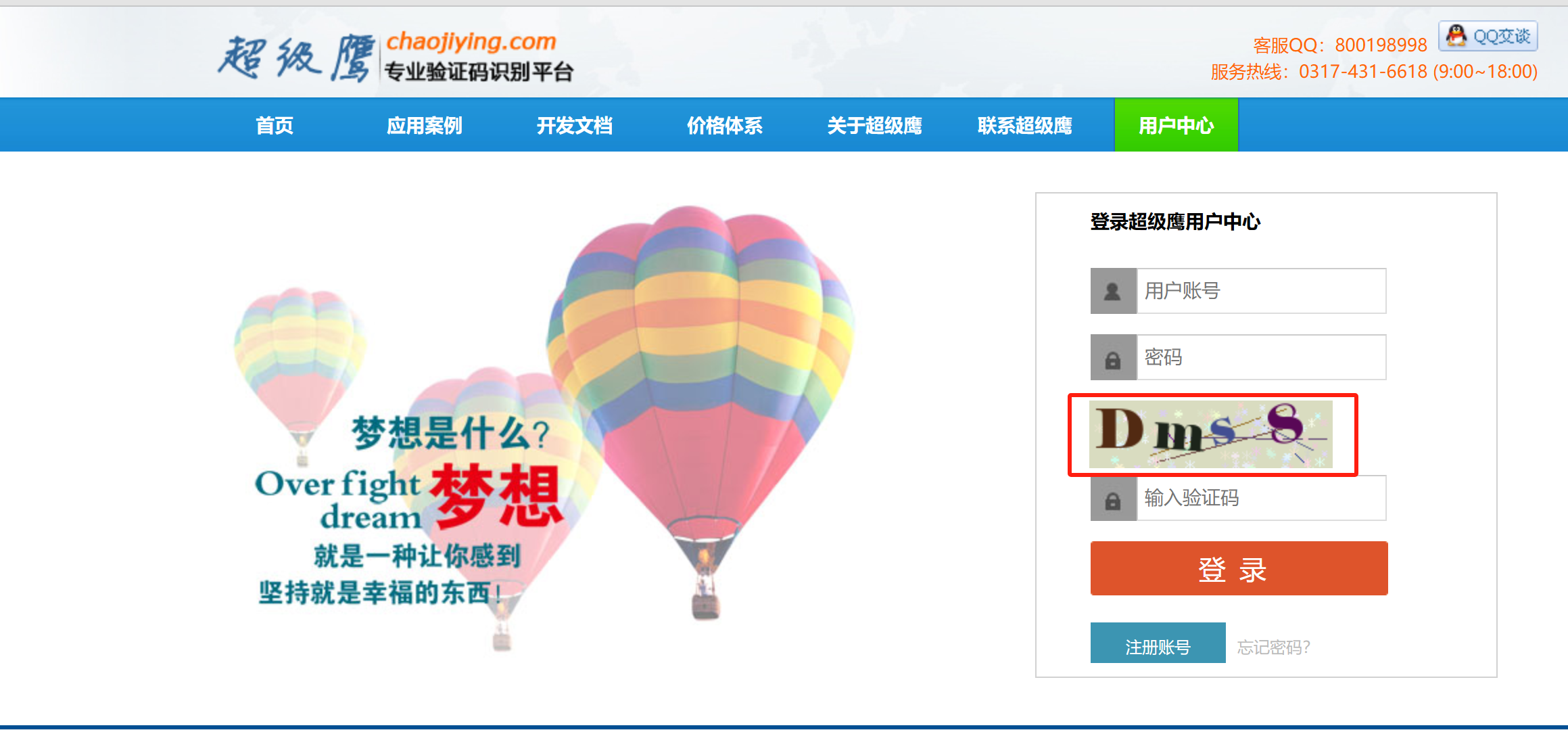
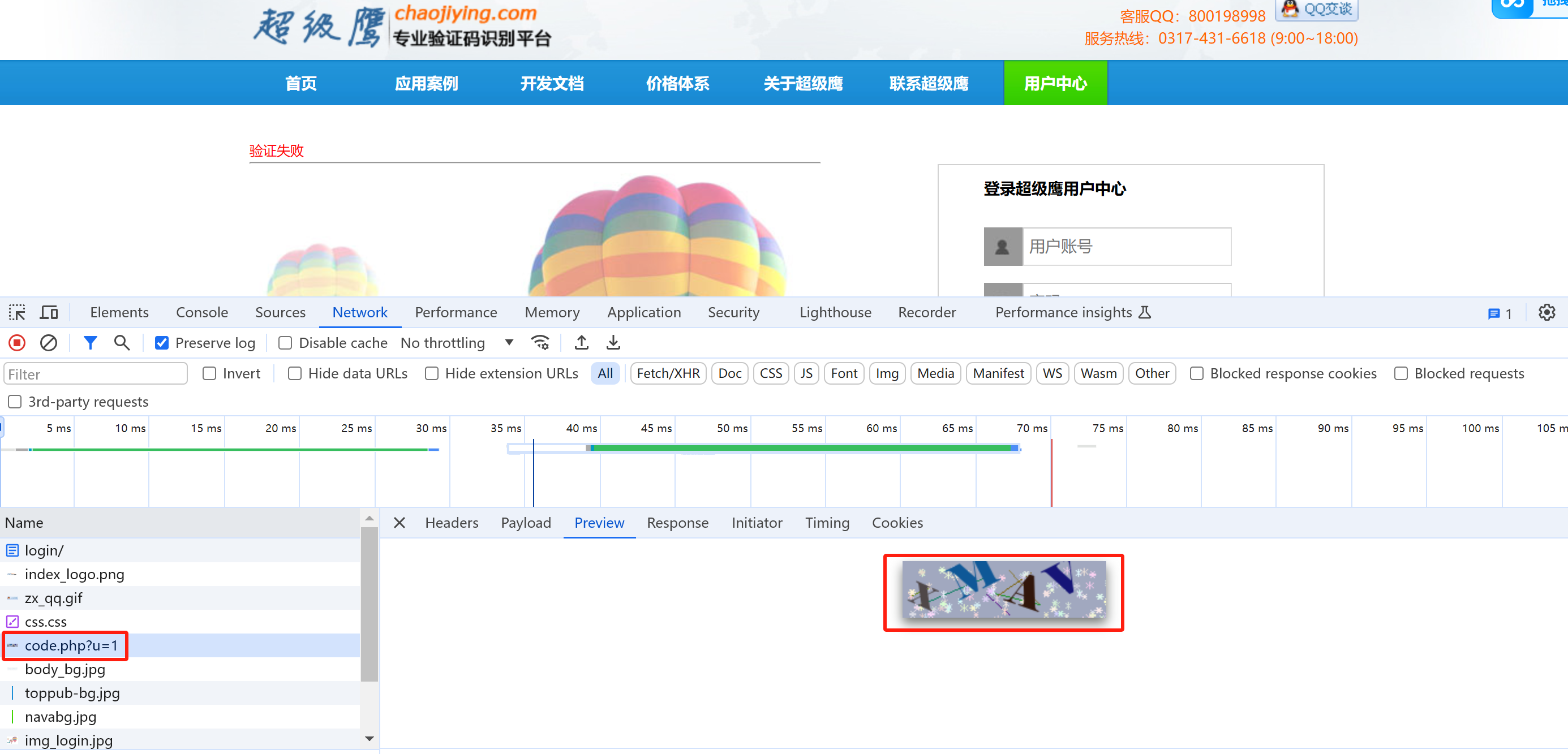
对于 超级鹰 :网站登陆页面,如下图所示:其会显示一个图像验证码,要想破解这类网站,就需要能够识别图像验证码中的字符
抓包分析,一打开登陆界面,其会自动向后台发送一个请求,获取一个图像验证码,且该同一链接地址多次请求,返回的结果均是不同的
对于其点击登陆按钮发送的登陆请求,抓包如下图所示:
综上所述,该问题的难点就在于验证码的识别问题
破解步骤:
发送请求获取验证码
这个问题比较棘手,因为发现,同一个图片地址,每次请求时,其返回的图片都是不一样的
那么他是如何将验证码与登陆关联起来的呢?通过同一会话session关联起来的
识别验证码内容
```python
python中ocr识别库: ddddocr
如果精度要求比较高,可以找一些第三方收费服务:百度直接搜:打码平台 一般会支持各种类型的验证码识别
创建ocr对象 ocr = ddddocr.DdddOcr()
加载图片 with open(“1.png”,”rb”) as f:
image = f.read()
识别图片内容 code = ocr.classification(image)
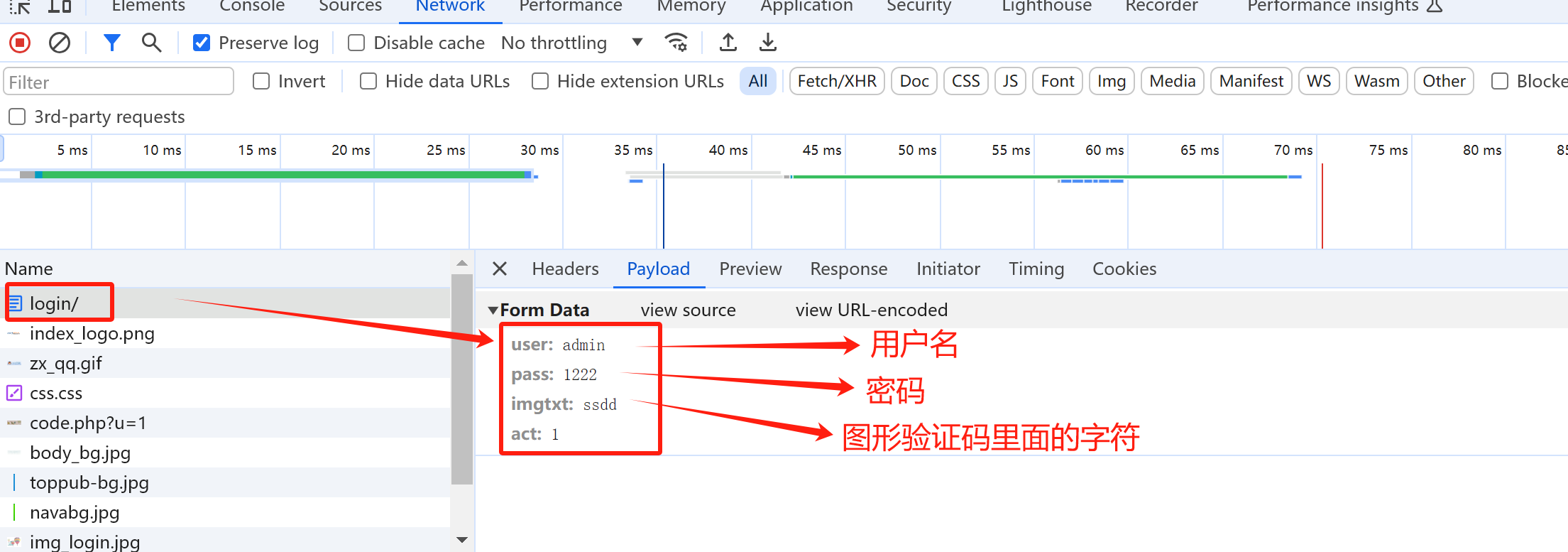
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 - 发送登陆请求 **破解超级鹰网站登陆页面代码示例** ```python import requests import ddddocr """ 流程: ①请求网站,获取图像验证码图片 ②调用第三方库识别图像验证码文本 ③构造请求,发送登陆请求 注意:这整个过程需在同一会话session中进行 """ session = requests.session() #获取图形验证码 codeUrl = "https://www.chaojiying.com/include/code/code.php?u=1" codeImage = session.get(url=codeUrl).content with open("code.png","wb") as f: f.write(codeImage) #调用第三方库识别图像验证码 ocr = ddddocr.DdddOcr() code = ocr.classification(codeImage) print("验证码:",code) #构造登陆请求 loginUrl = "https://www.chaojiying.com/user/login/" params={ "user": "HustRich", "pass": "wu123456", "imgtxt": code, "act": 1 } headers={ "User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/125.0.0.0 Safari/537.36" # ,"Cookie":"PHPSESSID=c2s08og1j8244us3qc4ub9d217; __51cke__=; __tins__16851773=%7B%22sid%22%3A%201716036582790%2C%20%22vd%22%3A%203%2C%20%22expires%22%3A%201716039030500%7D; __51laig__=4" } response = session.post(url=loginUrl,data=params,headers=headers) print(response.content) with open("res.html","wb") as f: f.write(response.content)
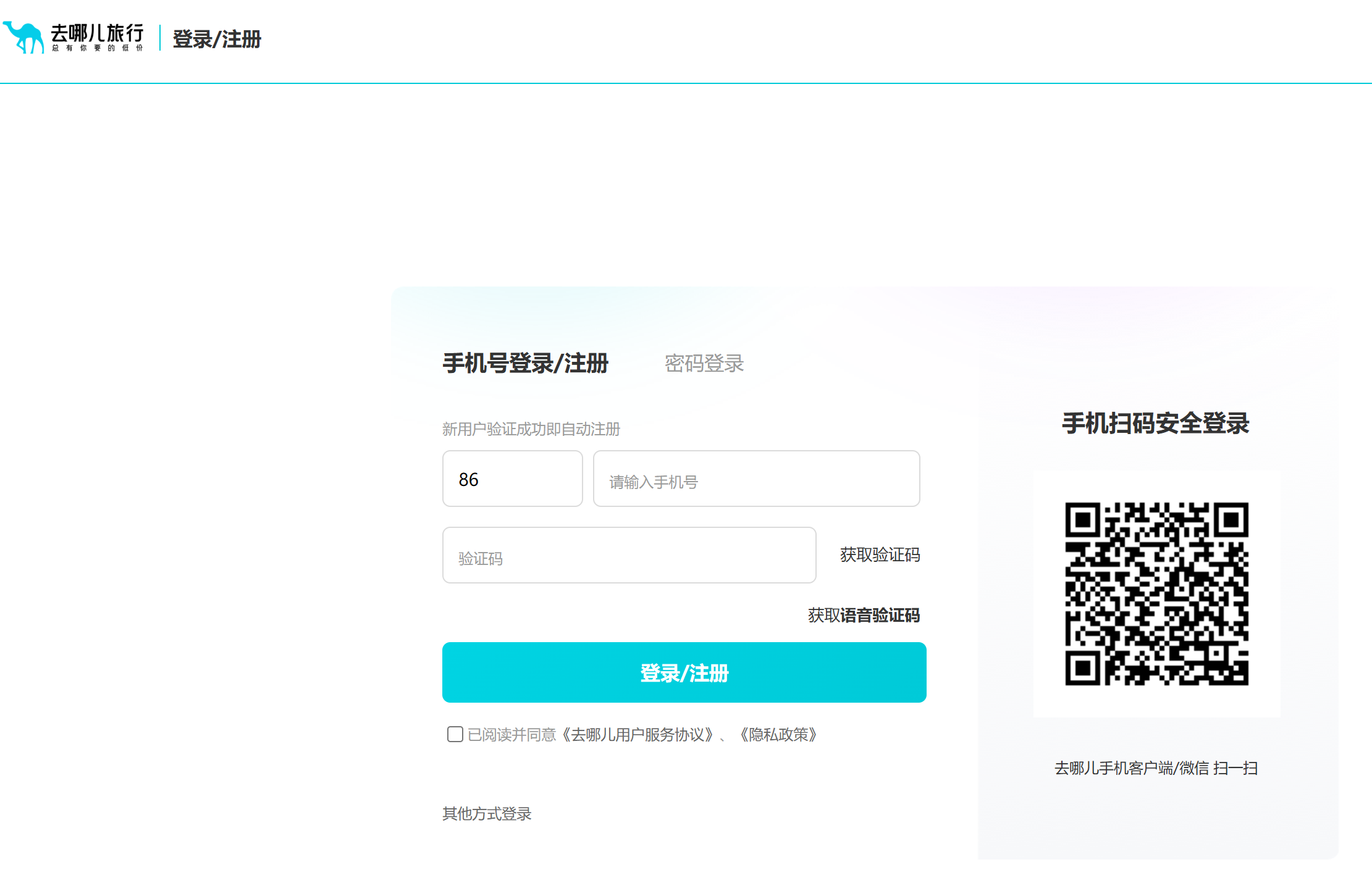
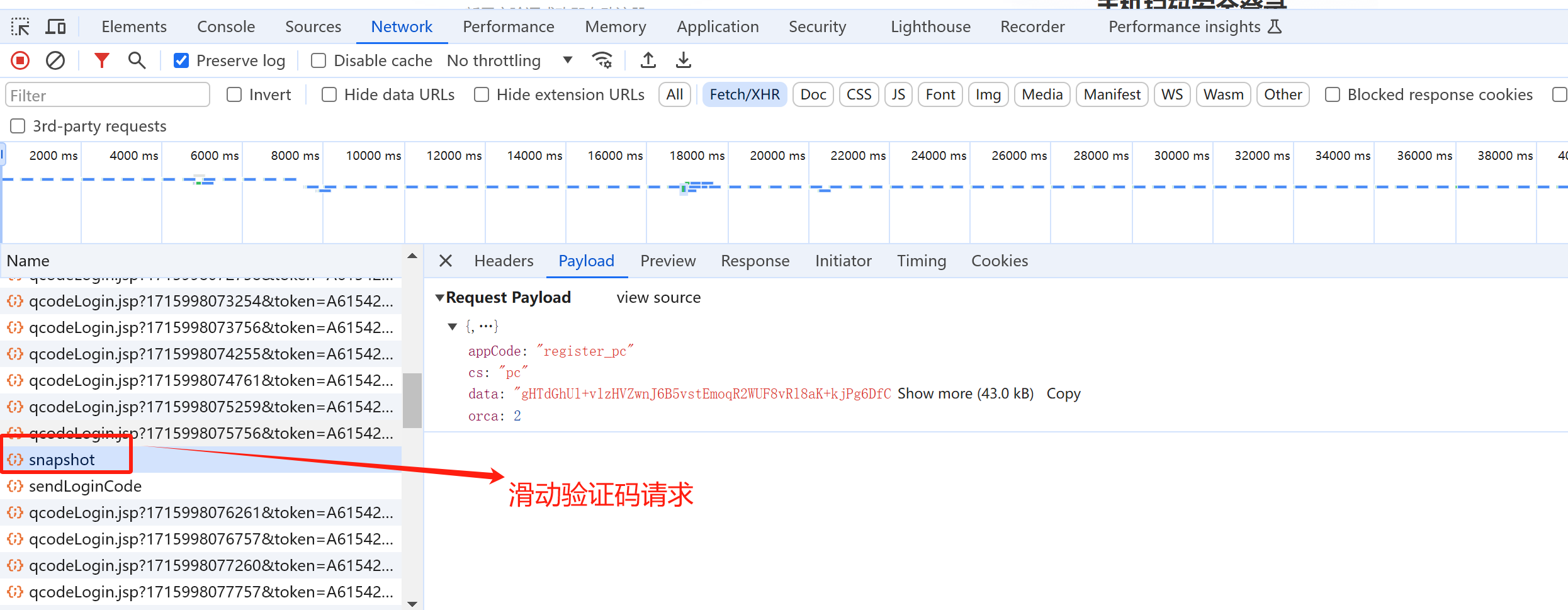
js逆向:滑动验证码的轨迹破解 案例网站:去哪儿
需求分析
我们输入手机号,然后点击获取验证码,会弹出一个滑动验证码窗口,经过验证之后才会收到验证码,然后点击登陆注册,此过程向后端的请求包括:
滑动验证码的请求
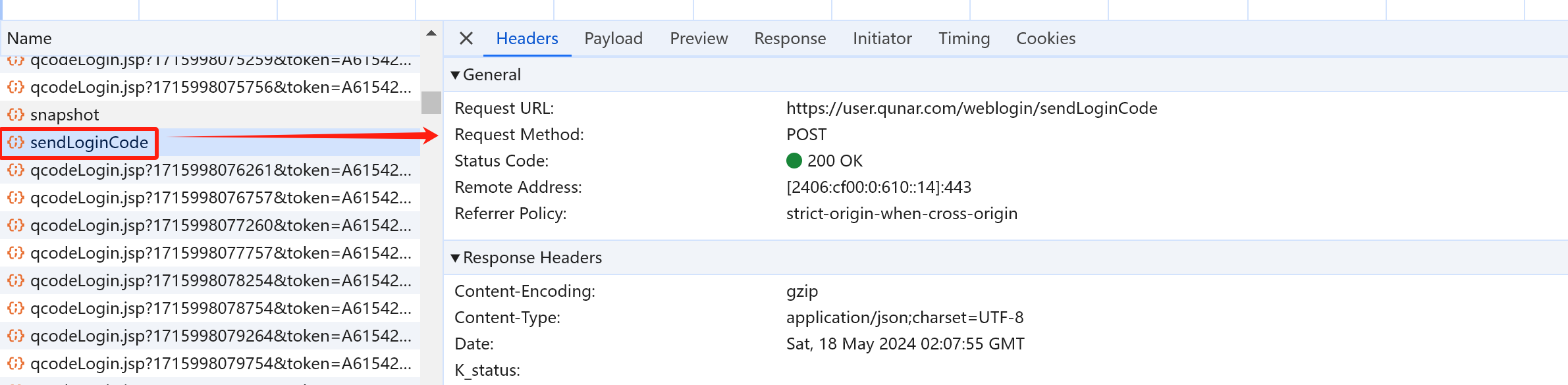
获取手机验证码的请求
登陆接口的请求
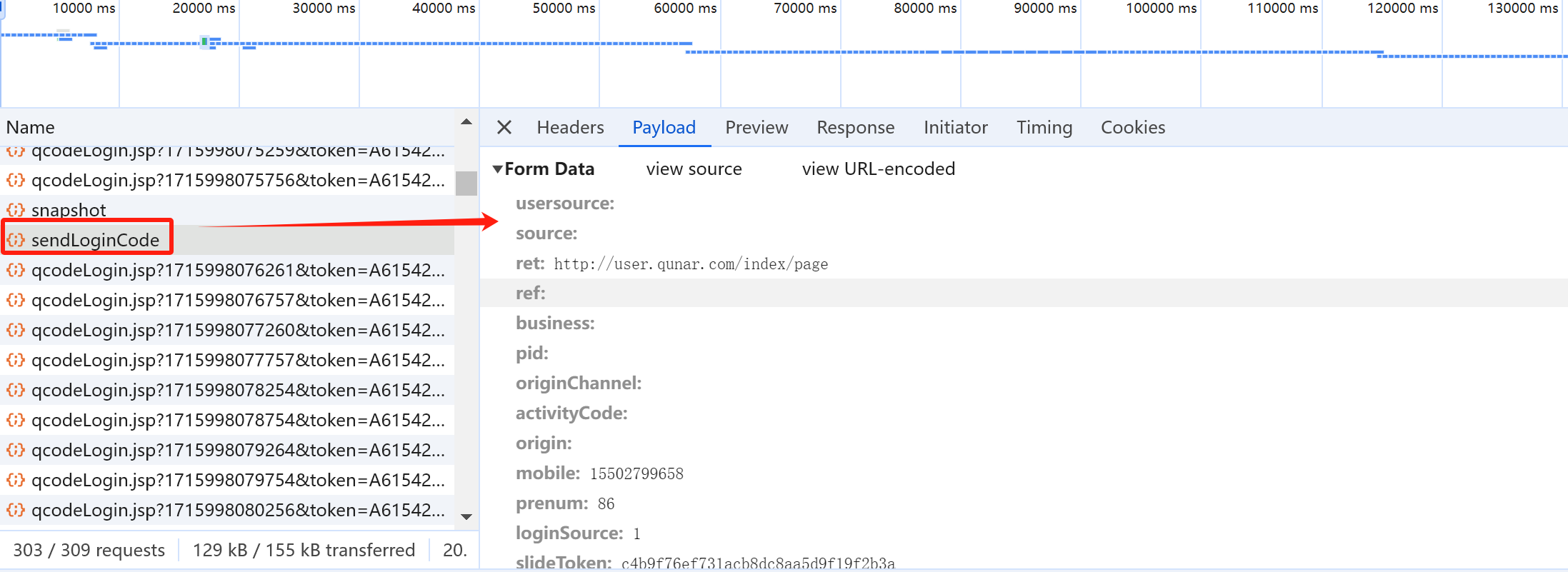
滑动验证码请求
只有将滑动验证码拖动到最右端才能成功发送该请求
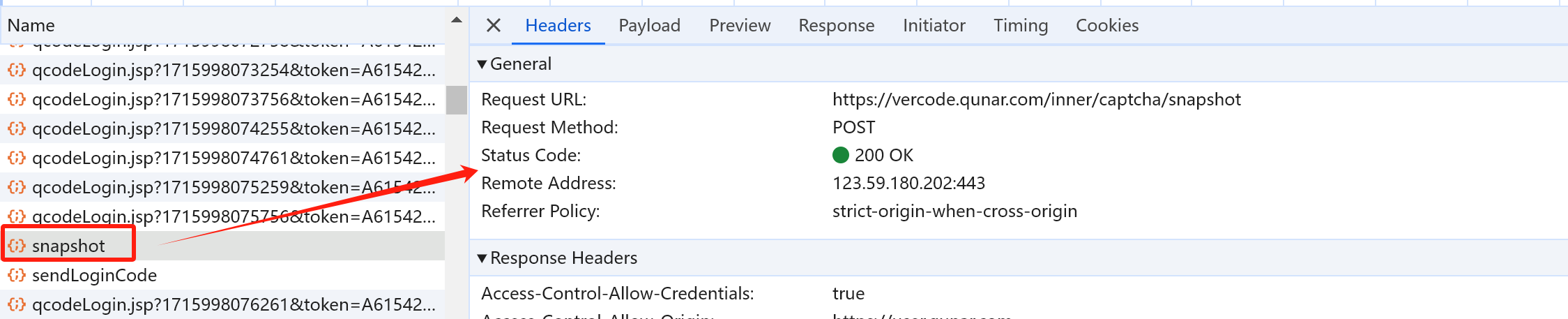
观察滑动验证码请求参数,发现其中有一个未知的参数 data
手机验证码请求
登陆接口请求
验证码破解相关知识等后续有需求再了解
异步爬虫 当我们有大量数据需要抓取时,总的抓取时间会比较长,这个时候,如果需要提高数据的抓取效率,需要用到多线程异步并发爬取
该方法缺陷,并发会导致短时间对目标网站服务器大量请求,使得目标网站压力过大,如果被检测,可能触发一系列的反爬机制
该方法一般需要配合代理IP去使用,每次请求从不同ip发出,这样即使访问很频繁,由于请求来自于不同ip,被检测概率会比较低
抓取需求 目标网站:https://www.myfreemp3.com.cn/
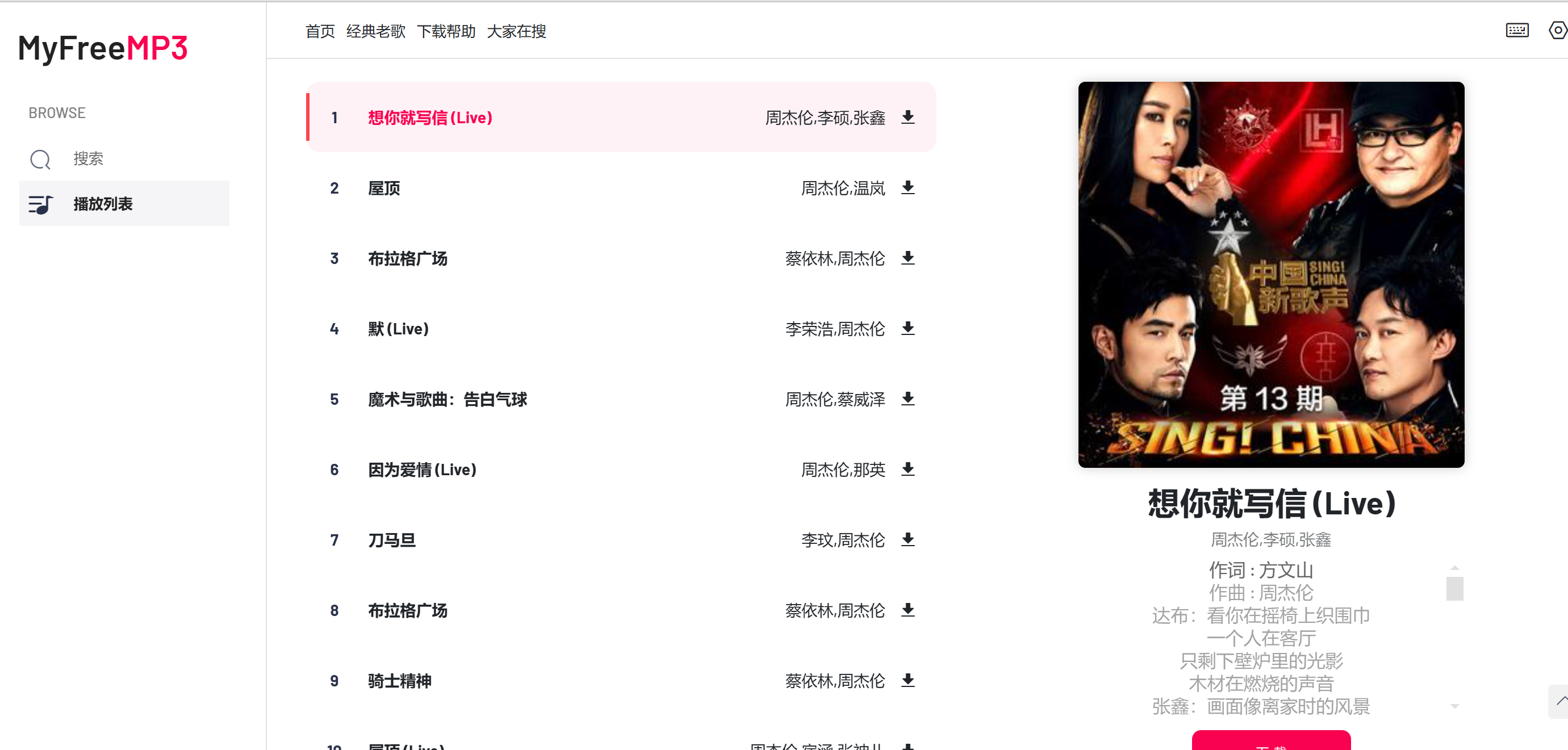
我们的目标是抓取该网站上周杰伦所有歌曲
思路分析 实现思路
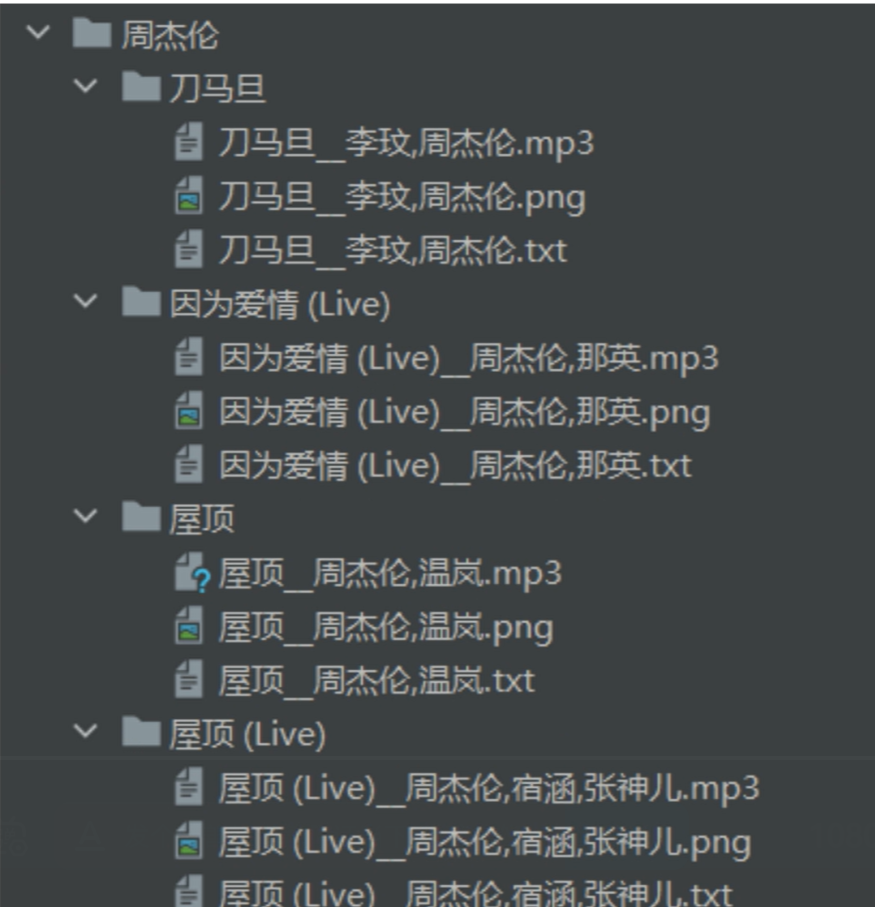
先抓取搜索歌手所有的歌曲,提取歌曲名、歌手、封面图、歌词信息
然后再去下载歌曲、封面、歌词保存为文件
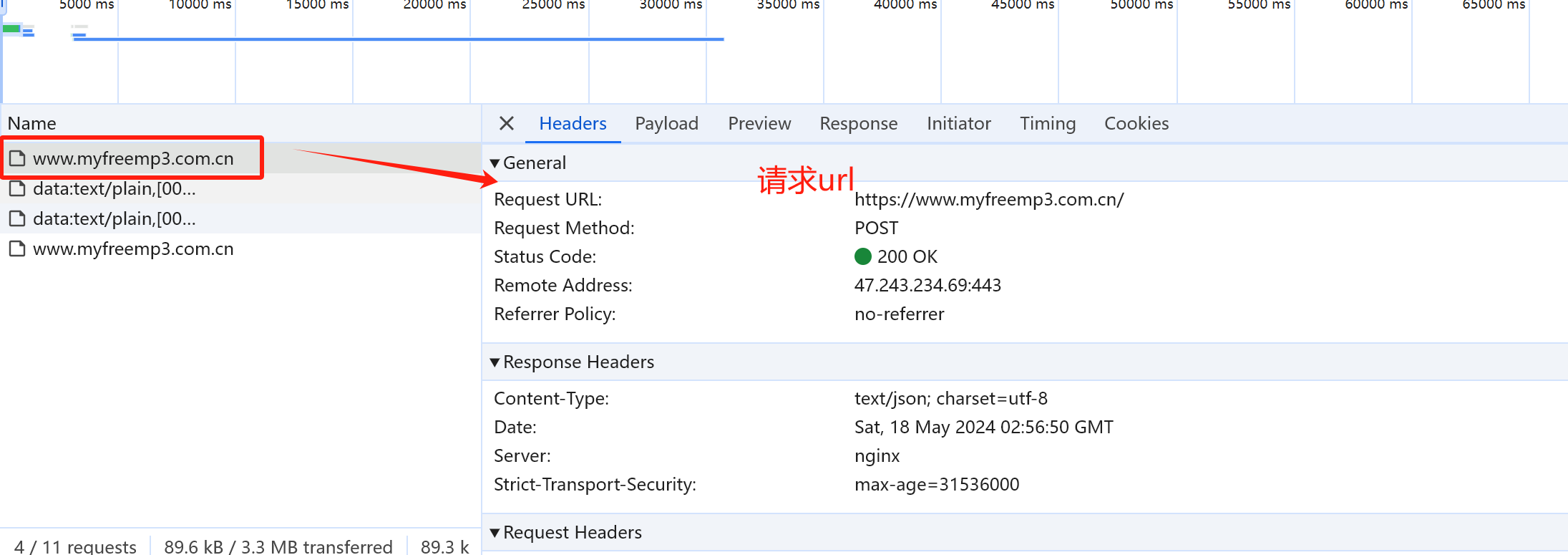
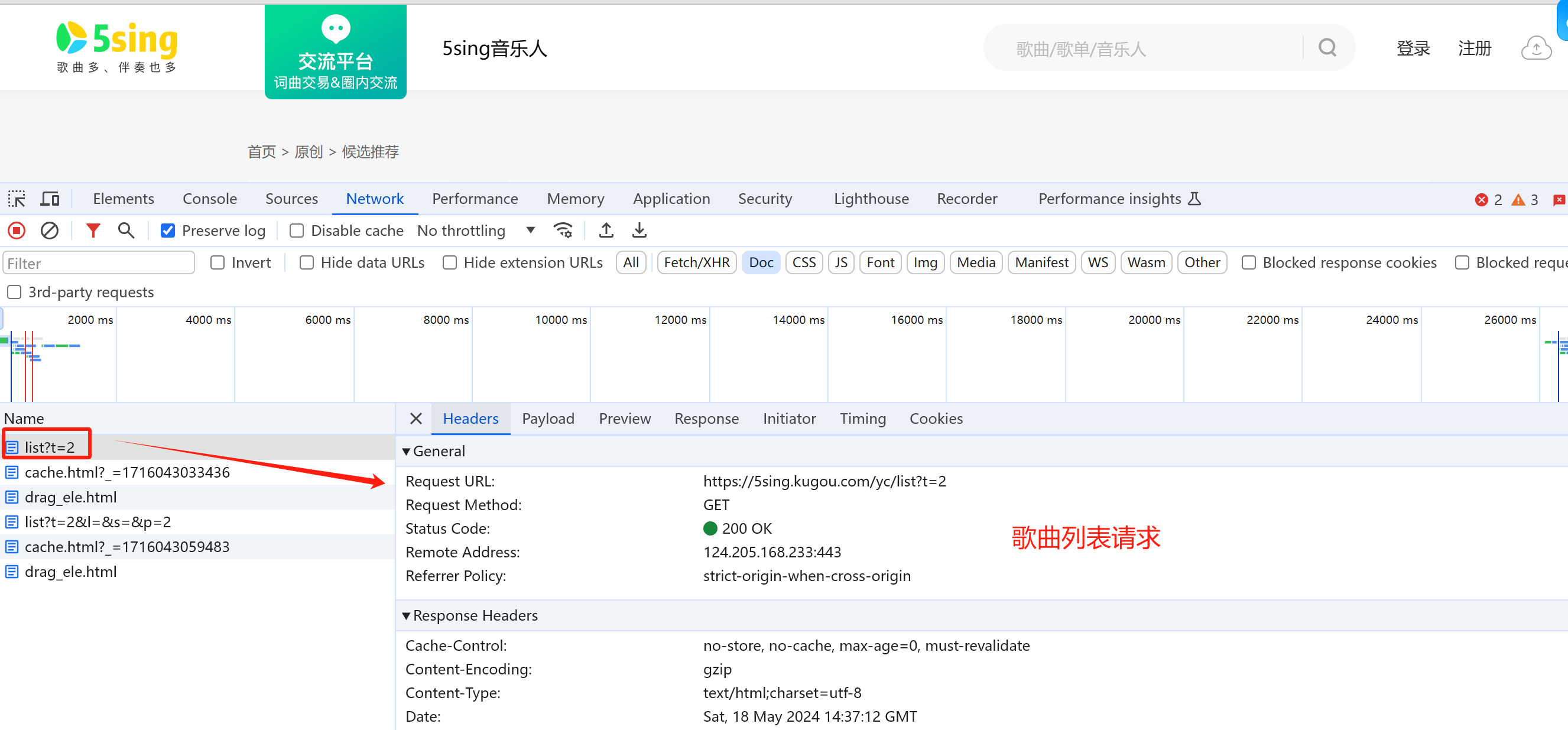
获取歌曲列表接口 抓包分析:
歌曲列表接口:
url地址:
请求方法:
参数:
input: 歌手名
filter: name
page: 页码
type: netease
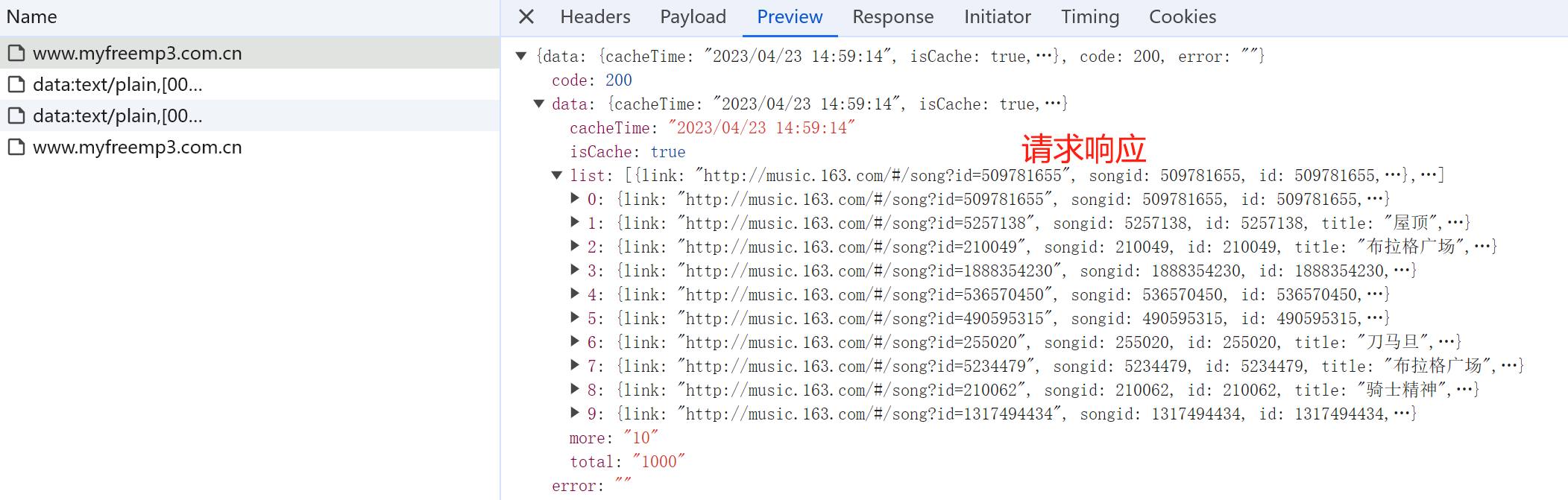
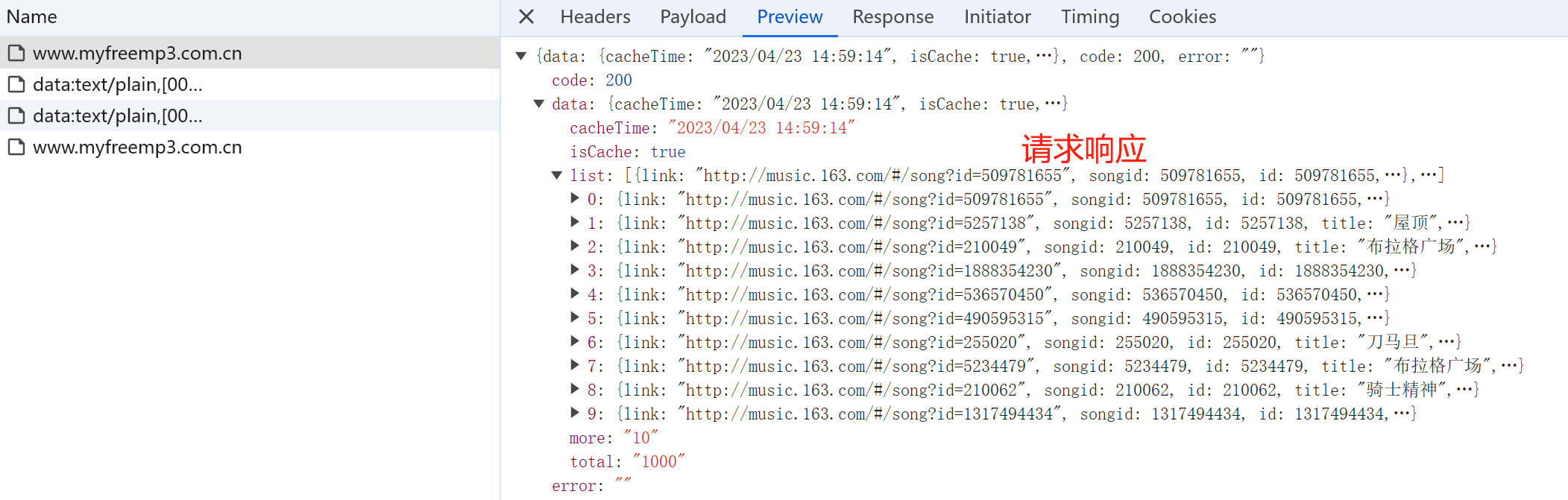
返回响应:
单线程下载 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 """ 分析: 抓取网站:https://www.myfreemp3.com.cn/ 中指定歌手的歌曲: 下载数据包括: 歌曲封面图片、歌曲歌词文本文件,歌曲mp3资源文件 文件存储格式: 歌手名: 歌曲名: 歌曲名_作者.png 歌曲名_作者.txt 歌曲名_作者.mp3 """ import requestsimport osclass CrawMusic : def __init__ (self,baseDir ): self.url = "https://www.myfreemp3.com.cn" self.headers={ "User-Agent" :"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/125.0.0.0 Safari/537.36" ,"X-Requested-With" :"XMLHttpRequest" } self.params={ "input" : "周杰伦" , "filter" : "name" , "page" : 1 , "type" : "netease" } self.baseDir = baseDir def sendRequest (self,name,pageIndex ): """ :param name: 歌手姓名 :param pageIndex: 当前页码 :return: """ self.params["name" ]=name self.params["page" ]=pageIndex response = requests.post(url=self.url, data=self.params, headers=self.headers) data = response.json()["data" ]["list" ] curSaveDir = os.path.join(self.baseDir,name) if not os.path.exists(curSaveDir): os.makedirs(curSaveDir) self.parseData(curSaveDir,data) def parseData (self,curSaveDir,data ): """ :param curSaveDir: 该歌手数据存储根目录 :param data: 需要被解析的数据 :return: """ for item in data: title = item["title" ] author = item["author" ] pic = item["pic" ] tex = item["lrc" ] mp3Link = item["url" ] curMusicSaveDir = os.path.join(curSaveDir, title) if not os.path.exists(curMusicSaveDir): os.mkdir(curMusicSaveDir) print ("benign dowmload {}" .format (title)) curPicSavePath = os.path.join(curMusicSaveDir, title + ".png" ) self.downloadFile(pic, curPicSavePath) curTexSavePath = os.path.join(curMusicSaveDir, title + ".txt" ) with open (curTexSavePath, "w" ) as f: f.write(tex) curMp3SavePath = os.path.join(curMusicSaveDir, title + ".mp3" ) self.downloadFile(mp3Link, curMp3SavePath) else : print ("歌曲{}已被下载,无需重复下载" .format (title)) def downloadFile (self,url, path ): response = requests.get(url) if response.status_code == 200 : with open (path, "wb" ) as f: f.write(response.content) else : print (url+" 下载失败" ) if __name__=="__main__" : crawDownload = CrawMusic(r"E:\tempData\musics" ) crawDownload.sendRequest("周杰伦" ,1 )
异步下载 上面代码是单线程下载,而且只是下载单页数据,当需要下载大量数据时,就必须采用多线程异步下载
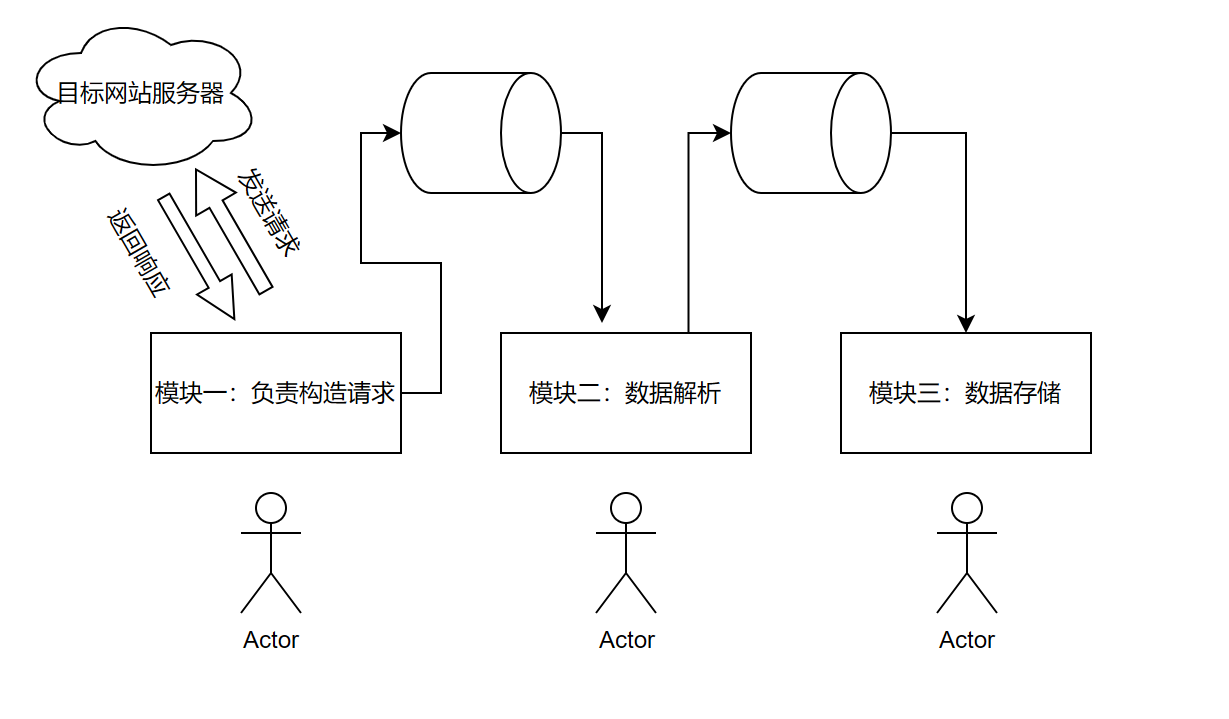
整个爬虫其实主要分为以下三个模块:
发送请求获取响应
数据解析
数据存储
如下图所示,对于这三个模块我们可以进行异步处理,模块一线程请求后的数据进入一个管道,模块二线程从管道中拿取数据进行解析,然后解析后的结果放入另一个管道,模块三线程从管道二中拿取解析后的数据进行存储,这个过程,三个模块相互独立,如果哪个部分耗时较多,可以采用多线程进行处理
多线程代码示例
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 """ 分析: 抓取网站:https://www.myfreemp3.com.cn/ 中指定歌手的歌曲: 下载数据包括: 歌曲封面图片、歌曲歌词文本文件,歌曲mp3资源文件 文件存储格式: 歌手名: 歌曲名: 歌曲名_作者.png 歌曲名_作者.txt 歌曲名_作者.mp3 并发下载: 请求、数据解析、数据存储三个部分用多个不同线程处理 各个线程之间用 queue.Queue来进行数据传递,该对象是线程安全的 queue的用法参考:https://blog.csdn.net/songpeiying/article/details/131761990 queue = queue.Queue() queue.put() 添加数据 使用put()方法将元素放入队列。如果队列已满,put()方法会阻塞直到有空余空间 queue.get() 获取数据 使用get()方法从队列中取出元素。如果队列为空,get()方法会阻塞直到有元素可用 queue.get(timeout=xx) 等待xx秒如果还未获取数据则会报错,如果不添加timeout参数则会一直阻塞 """ import queuefrom concurrent.futures.thread import ThreadPoolExecutorimport requestsimport osclass CrawMusic : def __init__ (self,baseDir ): self.url = "https://www.myfreemp3.com.cn" self.headers={ "User-Agent" :"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/125.0.0.0 Safari/537.36" ,"X-Requested-With" :"XMLHttpRequest" } self.params={ "input" : "周杰伦" , "filter" : "name" , "page" : 1 , "type" : "netease" } self.baseDir = baseDir self.responseDataQueue = queue.Queue() self.parseDataQueue = queue.Queue() def sendRequest (self,name,pageIndex ): """ :param name: 歌手姓名 :param pageIndex: 当前页码 :return: """ self.params["input" ]=name self.params["page" ]=pageIndex response = requests.post(url=self.url, data=self.params, headers=self.headers) data = response.json()["data" ]["list" ] curSaveDir = os.path.join(self.baseDir,name) if not os.path.exists(curSaveDir): os.makedirs(curSaveDir) self.responseDataQueue.put((curSaveDir,data)) def parseData (self ): """ :param curSaveDir: 该歌手数据存储根目录 :param data: 需要被解析的数据 :return: """ while True : try : curSaveDir, data = self.responseDataQueue.get(timeout=2 ) except queue.Empty: break for item in data: title = item["title" ] author = item["author" ] pic = item["pic" ] tex = item["lrc" ] mp3Link = item["url" ] curMusicSaveDir = os.path.join(curSaveDir, title) self.parseDataQueue.put((curMusicSaveDir,title,author,pic,tex,mp3Link)) def saveData (self ): while True : try : curMusicSaveDir, title, author,pic, tex, mp3Link = self.parseDataQueue.get(timeout=2 ) except queue.Empty: break if not os.path.exists(curMusicSaveDir): os.mkdir(curMusicSaveDir) print ("benign dowmload {}" .format (title)) curPicSavePath = os.path.join(curMusicSaveDir, title +"_" +author+ ".png" ) self.downloadFile(pic, curPicSavePath) curTexSavePath = os.path.join(curMusicSaveDir, title +"_" +author+ ".txt" ) with open (curTexSavePath, "w" ) as f: f.write(tex) curMp3SavePath = os.path.join(curMusicSaveDir, title +"_" +author+ ".mp3" ) self.downloadFile(mp3Link, curMp3SavePath) else : print ("歌曲{}已被下载,无需重复下载" .format (title)) def downloadFile (self,url, path ): response = requests.get(url) if response.status_code == 200 : with open (path, "wb" ) as f: f.write(response.content) else : print (url+" 下载失败" ) if __name__=="__main__" : crawDownload = CrawMusic(r"E:\tempData\musics" ) """ 多线程,我们采用线程池来进行处理 """ with ThreadPoolExecutor(max_workers=5 ) as pool: pool.submit(crawDownload.sendRequest,"蔡依林" ,1 ) pool.submit(crawDownload.parseData) pool.submit(crawDownload.saveData) pool.submit(crawDownload.saveData) pool.submit(crawDownload.saveData)
Cookie池和IP代理 多线程并发存在问题:同一时间向目标服务器发送请求过多,且请求来自于同一客户端,容易被对方察觉,触发反爬机制导致失败
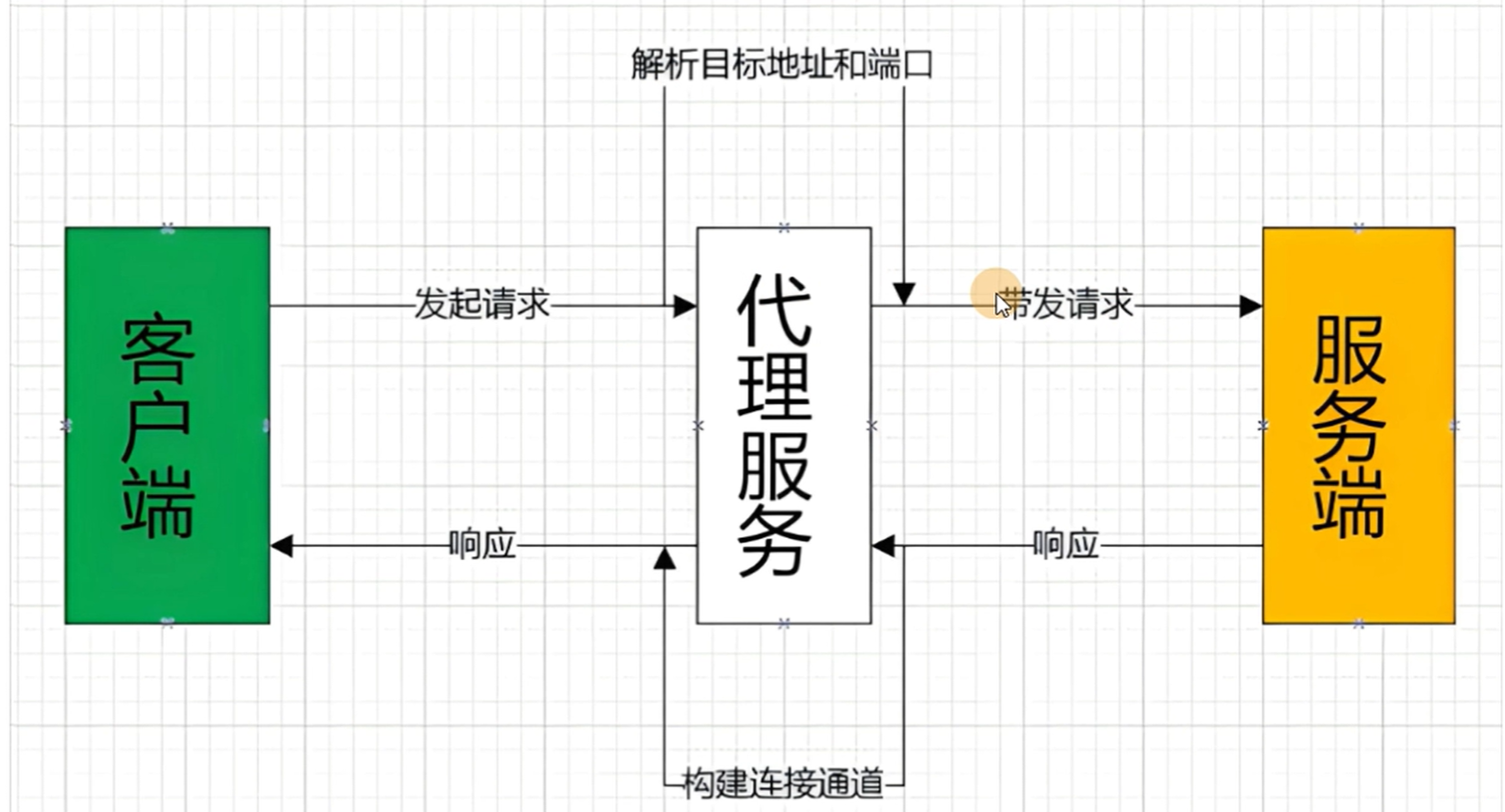
代理IP的使用 代理IP的基本概念 背景:为什么要使用代理
一段时间内,检测IP访问频率,访问太频繁会被识别成爬虫被对方屏蔽
使用代理IP可以让服务器以为不是同一客户端在请求
防止我们真实的IP地址被泄露,被追究
使用代理的请求过程
代理IP的获取 目前有许多平台会提供代理IP的服务,且一般注册之后都会赠送一些免费使用的额度
代理IP平台 在python代码中如何配置代理 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 import requestsurl = "https://www.baidu.com" headers={ "User-Agent" :"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/125.0.0.0 Safari/537.36" } ip ="122.239.153.110" port =40020 proxies={ "http" :f"htpp://{ip} .{port} " } response = requests.get(url=url,headers=headers,proxies=proxies) print (proxies)print (response.content)
动态ip池 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 import requestsimport random""" 天启平台有教程,更具生成的api链接发送get请求可以获取代理Ip列表 每次在爬虫时,随机从列表中选择一个代理ip """ class SpiderCraw : def __init__ (self ): self.proxyGetUrl = "http://api.tianqiip.com/getip?secret=ka9cjsm0egycakir&num=10&type=json&port=1&time=5&mr=1&sign=d50e433630f39d20c428a0d5c6c033e7" self.ipList = requests.get(self.proxyGetUrl).json()["data" ] def getProxyIp (self ): return random.choice(self.ipList) def getSendRequest (self ): proxyIp = self.getProxyIp() proxies = { "http" :"http://{}:{}" .format (proxyIp["ip" ],proxyIp["port" ]) } url = "https://www.baidu.com" requests.get(url=url,proxies=proxies) url = ipPool = requests.get(url) print (ipPool.json()["data" ])
Cookie池的搭建 爬虫中使用cookie的利弊 带上cookie好处
带上cookie的坏处
一套cookie往往对应一个用户的信息,请求太频繁容易被对方识别为爬虫
上面问题如何解决?使用多个账号,每次请求的cookie不一样即可
cookie池的搭建 思路分析
主备多个账号,越多越好
爬取数据之前对这些账号进行批量登录,并将cookie保存在本地cookie池中
需要登陆账号的可以这么做
不需要登陆账号的,可以启动多个浏览器,手动登陆,然后将cookie值复制存储在本地
爬虫执行之后,每次从cookie池中随机选择一个cookie
示例代码
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 import requestsimport randomclass CookieManager : def __init__ (self ): self.cookieList=[] self.userInfoList=[ {"userName" : "123321" ,"password" : "wwxxx1" }, {"userName" : "123322" , "password" : "wwxxx2" }, {"userName" : "123323" , "password" : "wwxxx3" }, {"userName" : "123324" , "password" : "wwxxx4" }, {"userName" : "123325" , "password" : "wwxxx5" } ] for userInfo in self.userInfoList: self.loginGetCookie(userInfo) for item in self.cookieList: print (item) def loginGetCookie (self,userInfo ): """ 登陆函数,并从响应中获取cookie,然后保存在cookie池中 :return: """ url="https://passport.china.com/logon" response = requests.post(url,data=userInfo) self.cookieList.append(response.cookies) def getCookie (self ): """ 供外部使用,随机从cookie池中选择一个cookie 外部使用时:直接在requests中以cookies参数进行传递 :return: """ return random.choice(self.cookieList) if __name__=="__main__" : cookieManager = CookieManager() print (cookieManager.getCookie())
Cookie池+IP池 同一个IP使用不同的Cookie,还是会出现同一个IP频繁请求,如果每个Cookie都绑定一组代理IP,这个时候就很难会被检测出来
基本思路:用不同ip去登陆不同账号,得到不同cookie,这样每一个代理Ipd都会对应多个cookie,在爬虫启动时,每次从ip_cookei池中选择一个ip,cookie对
综合项目实战案例 需求分析 某原创音乐网站数据抓取
需求:抓取某原创音乐平台整站数据
地址:https://5sing.kugou.com/
分页抓取该网站所有的原创音乐数据,一共50页
抓包分析 通过抓包分析,我们发现该网站数据不是Ajax请求,直接抓取请求页面即可获取对应数据
思路分析
获取歌曲列表、提取歌曲的歌名、歌曲首页地址
发送请求,获取页面的HTML
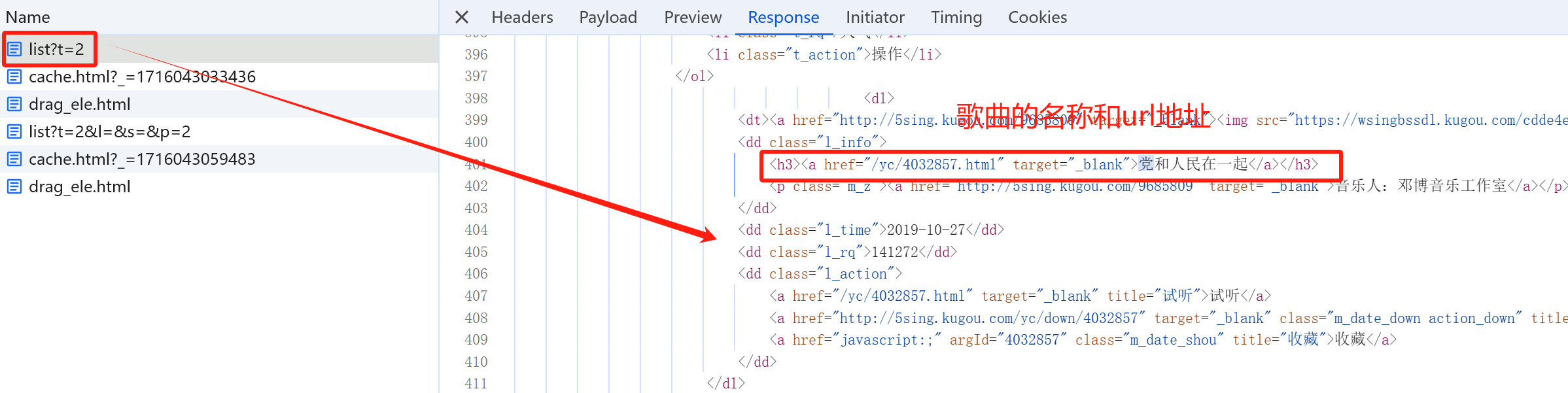
解析HTML,提取歌名和歌曲ID、首页地址
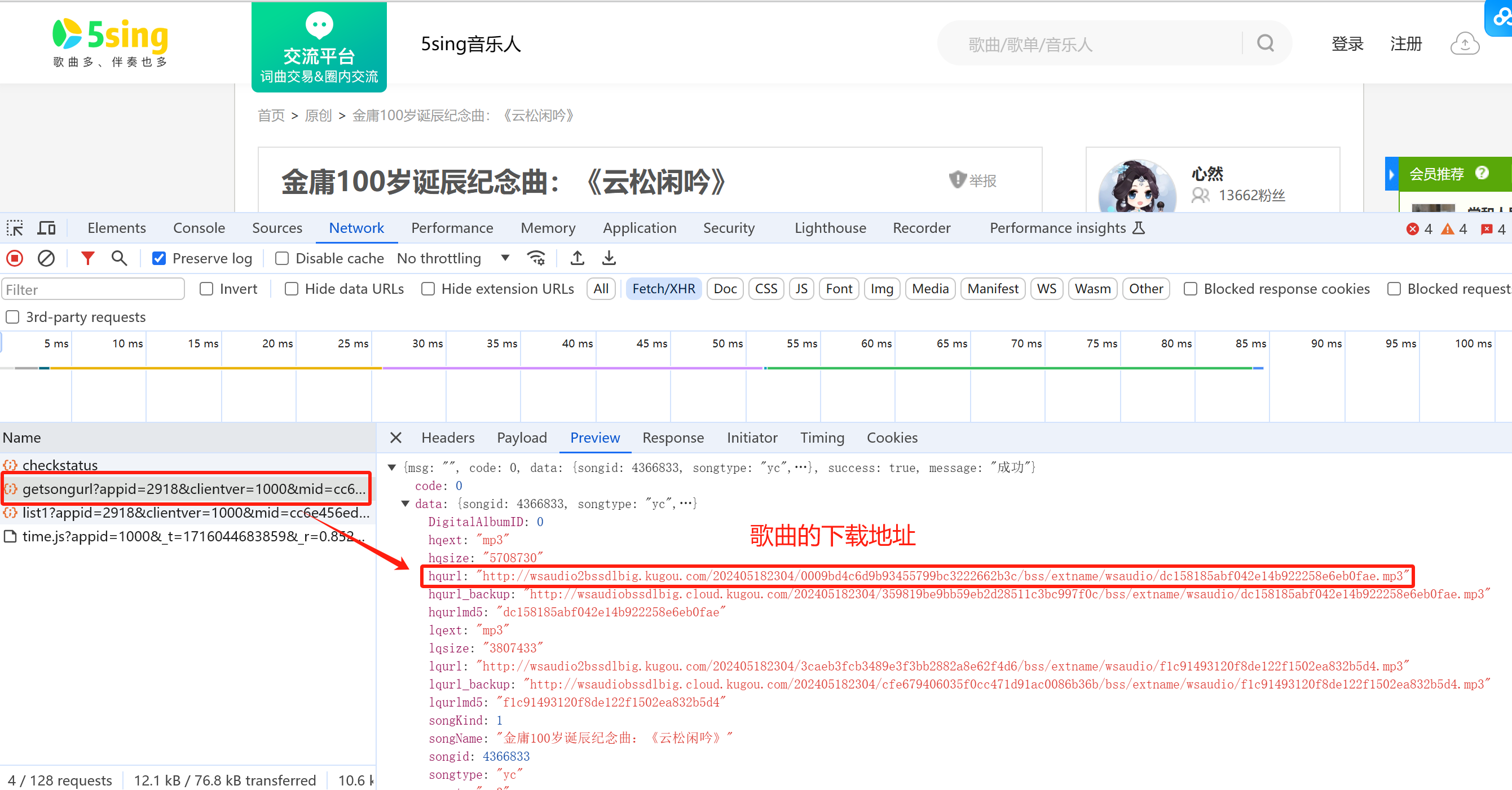
获取每首歌的下载地址
发送请求获取歌曲的下载地址
下载歌曲,保存在本地
下载歌曲,保存本地
数据量分析:一共50页,每页20条数据,要完整的下载一首歌的话,需要通过两次请求,第一次请求页面,获取歌曲id,第二次针对该歌曲地址,将其下载到本地
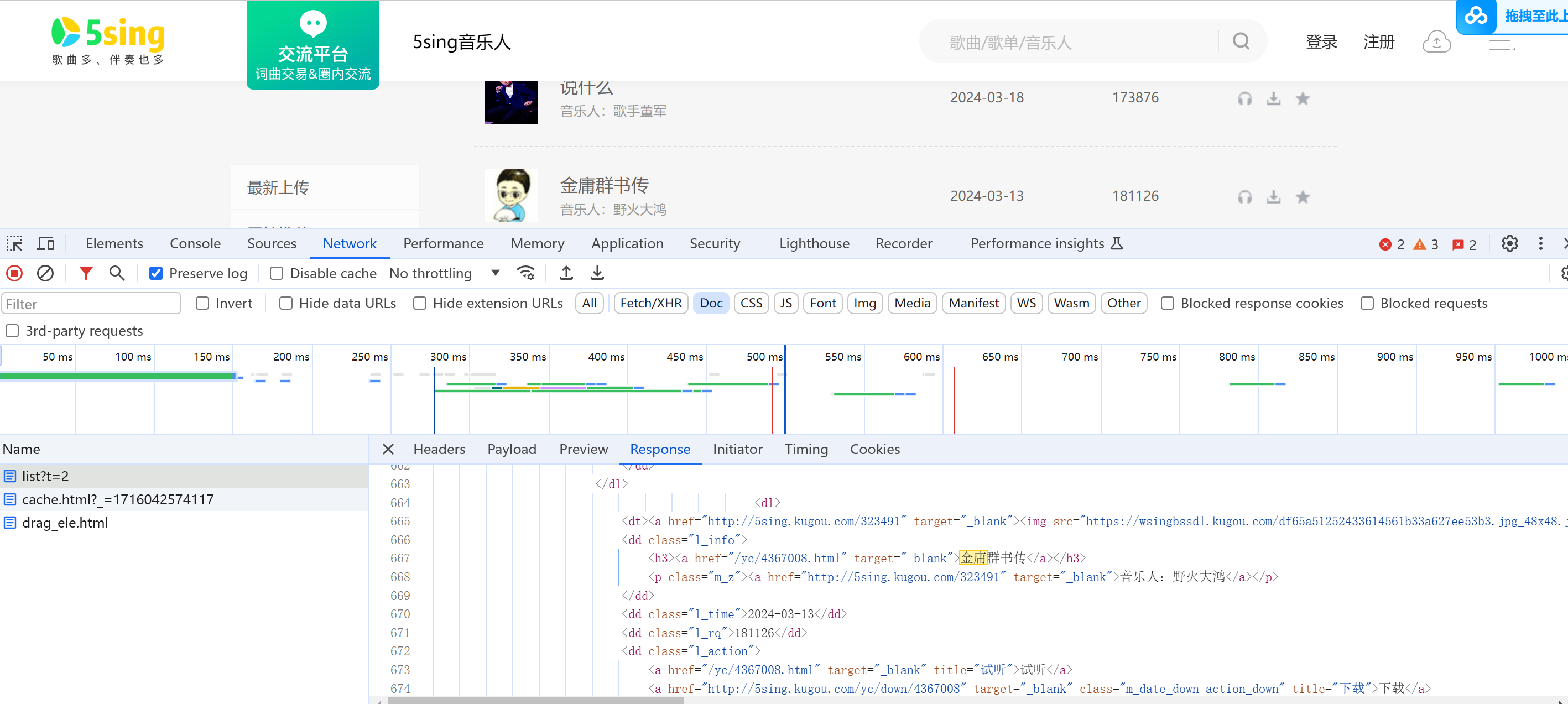
示例代码 爬取所有歌曲的名称和id数据 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 import requestsfrom lxml import etreeurl = "https://5sing.kugou.com/yc/list" headers={ "User-Agent" :"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/125.0.0.0 Safari/537.36" } for page in range (1 ,5 ): params={ "t" :2 , "l" :"" , "s" :"" , "p" :page } response = requests.get(url=url,headers=headers,params=params).content.decode("utf8" ) html = etree.HTML(response) dlList = html.xpath('//div[@class="lists"]/dl' ) for dlItem in dlList: title = dlItem.xpath('.//h3/a/text()' )[0 ] url = 'https://5sing.kugou.com{}' .format (dlItem.xpath('.//h3/a/@href' )[0 ]) id = dlItem.xpath('./dd[@class="l_action"]/a[@class="m_date_shou"]/@argid' )[0 ] print (title,url,id )
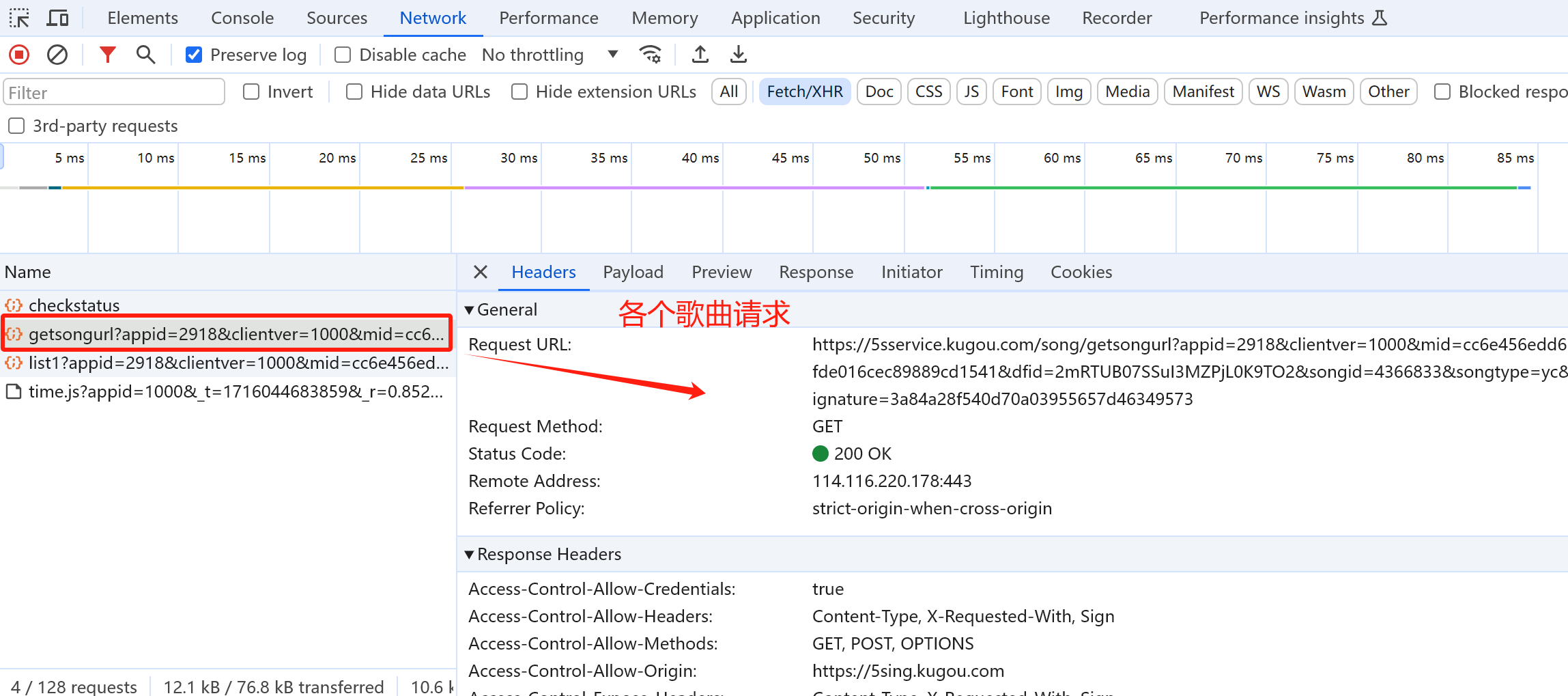
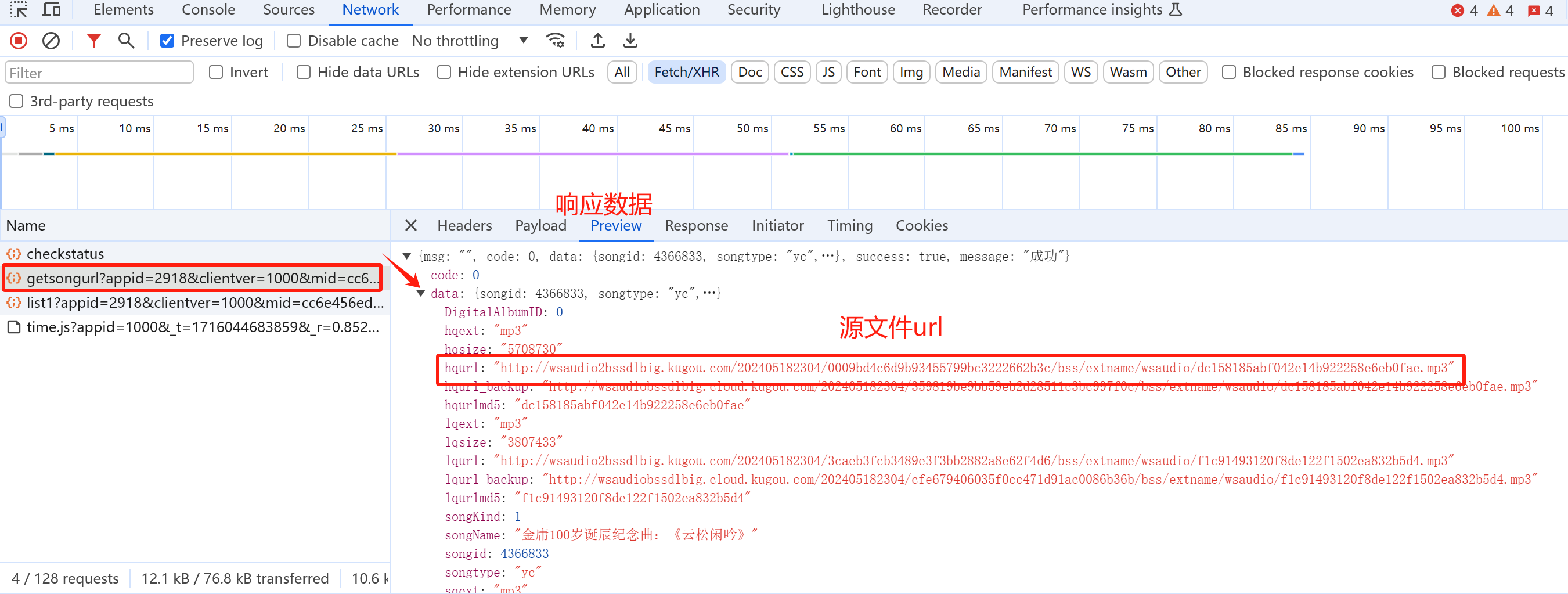
获取各个歌曲源文件的下载地址 >
抓包分析
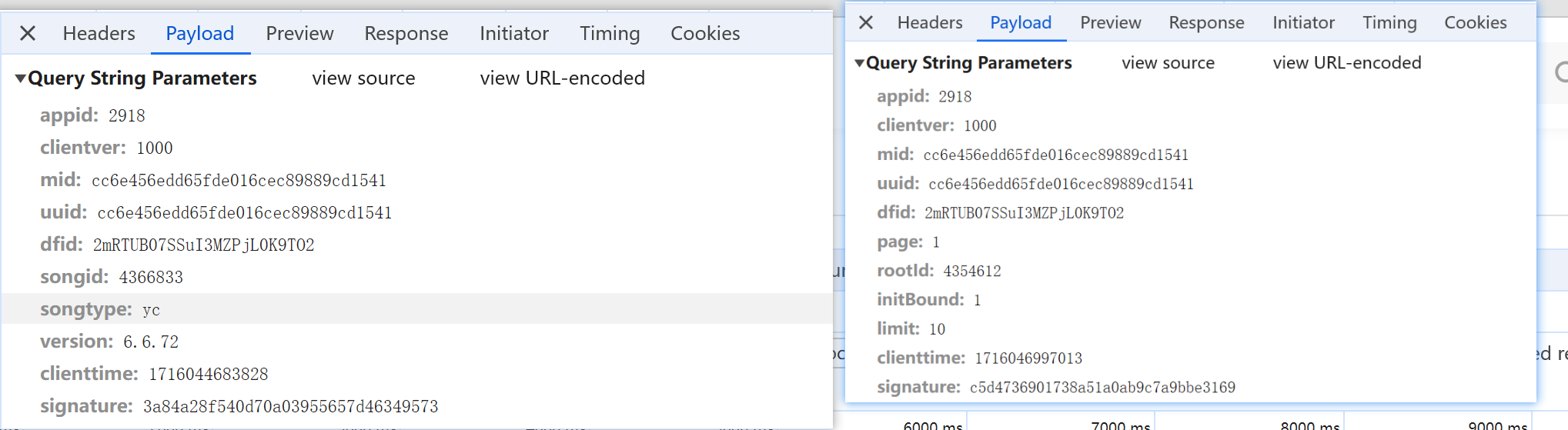
两个不同歌曲请求的参数对比:
我们发现只有songid和signature这两个参数不一样,songid即为我们前面抓取的歌曲id,而难点就在于signature不知从何而来
难点:参数signature不知从何而来,这个可能可能设计到js加密
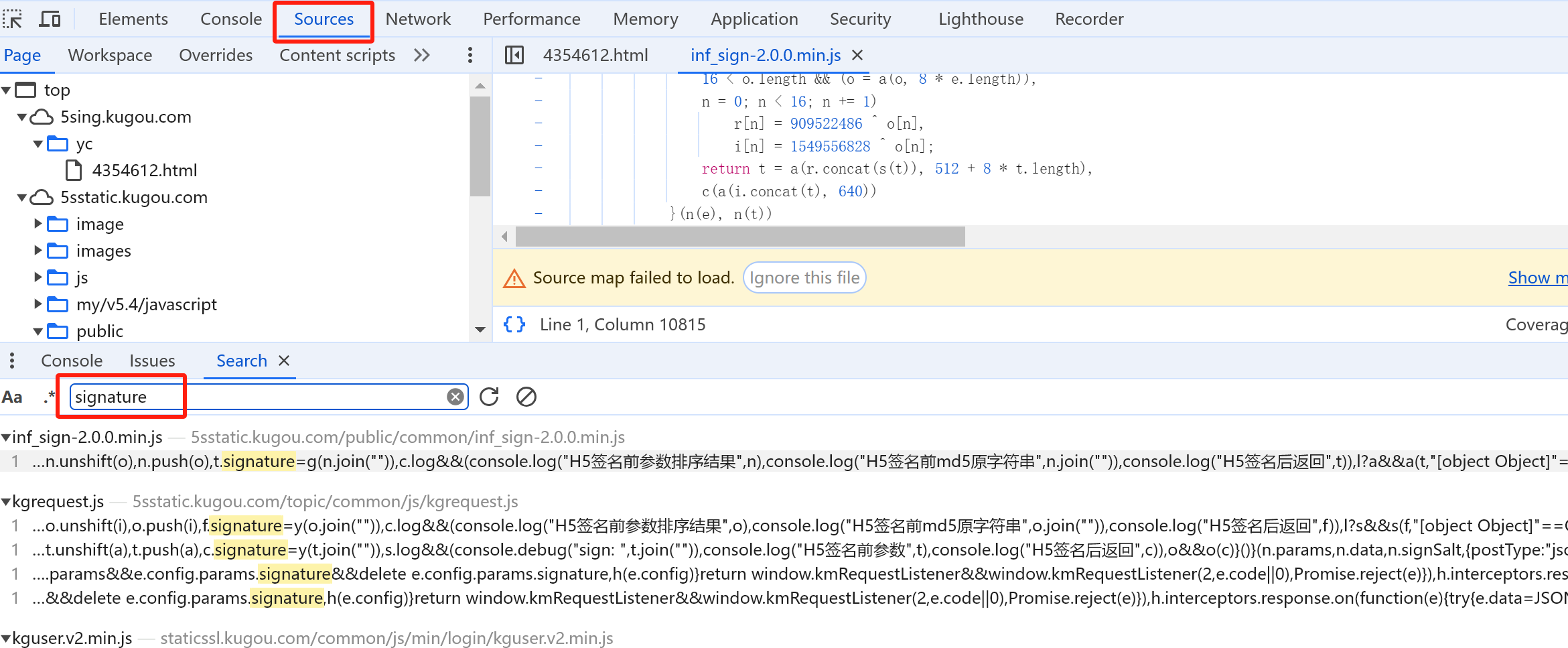
如何分析网站生成signature的js代码?
在所有源代码中搜索signature
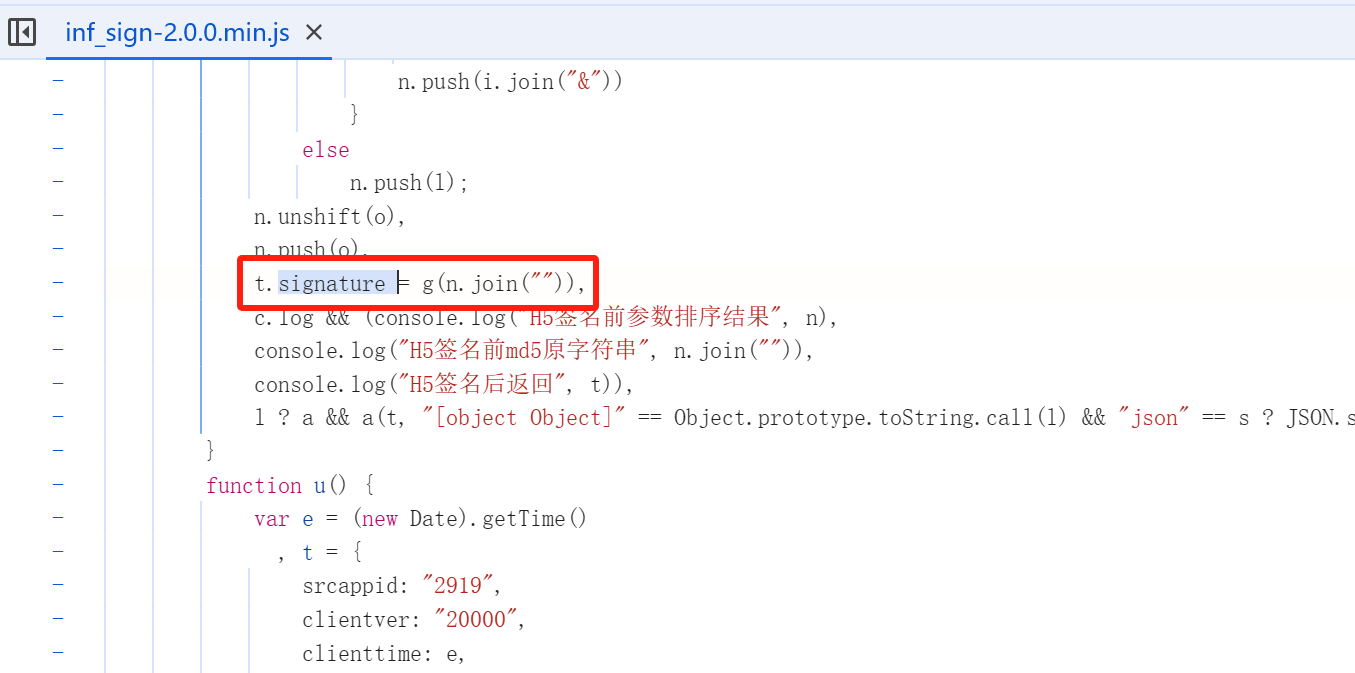
定位到该位置
我们在控制台执行,发现n的值为
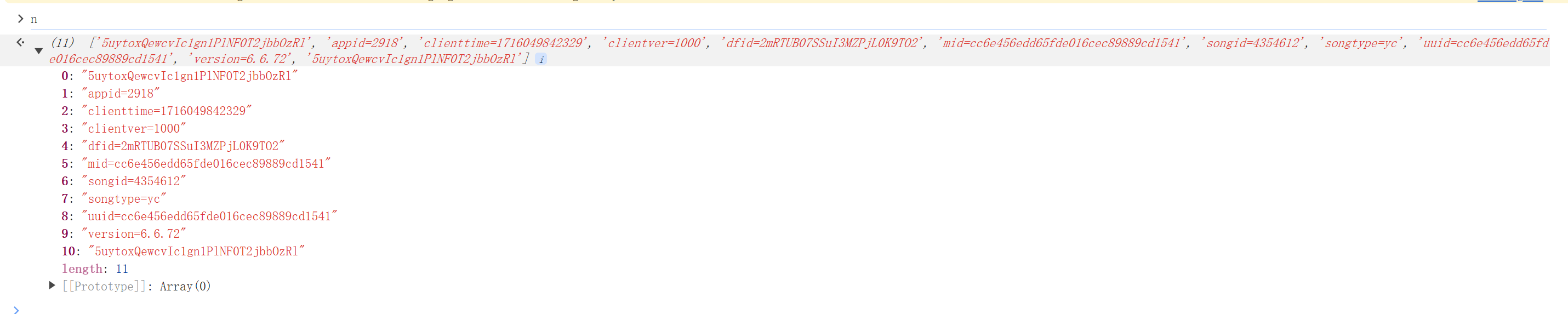
1 2 3 4 5 6 n的结构: 字符串: o = "5uytoxQewcvIc1gn1PlNF0T2jbbOzRl" 与请求参数的子字符串事项首位拼接得到拼接得到 即 n = o + params +o 我们经过多次实验发现字符串o为定值,不同请求、不同浏览器该值都是一致的
这个js代码比较复杂,我们无法用python代码等价复现,只能将js代码拷贝至本地,由python调用执行
其他补充知识 免费邮箱资源 针对账户限制,注册账号需要大量邮箱进行注册新的账号
需要很多邮箱怎么办?分享几个不错的办法可无限安全生成多个邮箱
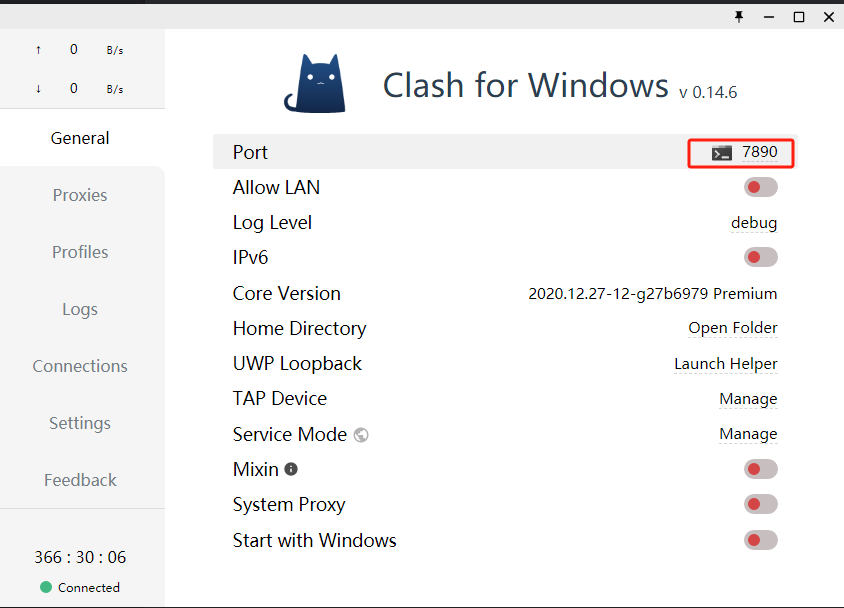
免费代理IP资源 设置自己本地的梯子IP地址:
打开clash软件,查看代理端口为7890,在代码首部添加如下代码,即可使用本地代理转发
1 2 3 os.environ["http_proxy" ] = "http://localhost:7890" os.environ["https_proxy" ] = "http://localhost:7890"
参考资料一
网站指纹反爬 背景 我们使用requests库访问网站https://www.digikey.cn时,无论怎么设置头部信息,均是返回403页面,但是用浏览器或者PostMan访问时,均可得到正常的页面结果,这种情况大概率就是遇到了**原生模拟浏览器 TLS/JA3 指纹的验证**,览器和postman 都有自带指纹验证,而唯独requests库没有。
解决办法 使用第三方库curl_cffi访问,即可解决这个问题,其可以模仿对浏览器指纹
1 2 3 4 5 from curl_cffi import requestsfrom lxml import etreer = requests.get("https://www.digikey.cn" , impersonate="chrome110" ) print (r.content.decode("utf8" ))
参考资料 某网站指纹反爬处理
JS逆向_浏览器JA3指纹信息
curl-cffif官方文档








 微信
微信 支付宝
支付宝