爬虫概述
爬虫概述
爬虫的作用
- 采集网络数据
- 自动化测试
- 实现一些脱离手动的操作,比如帮人投票、12306抢票、微信聊天助手
- 灰产,比如薅羊毛、网络攻击、做水军、刷单等
为什么要爬取数据(数据能做什么?)
- 聚合产品,比如新闻网站或者今日头条
- 搜索引擎,比如谷歌、百度
- 数据分析、人工智能的源数据
- 特定领域的数据服务,比如二手车估价、天气预报、去哪儿网等
爬虫的前置知识
- 计算机网络协议,比如http/https协议、tcp/ip协议、socket编程
- 一定的前端基础,不用太深入
- 正则表达式,主要是用来进行数据分析的
- 数据存储技术,比如分布式存储
- 并发处理技术,多线程、多进程、线程池等技术
- 图像识别(解决验证码反爬),机器学习算法(验证码、数据分析等后续操作)
爬虫中的难点问题
- 爬虫的采集以及更新策略
- 解决反爬
- 数据解析
- 海量数据存储
- 模拟登录(验证码识别)
- 爬虫的监控和部署
- 数据的去重,比如url去重、内容去重
爬虫中需要的网络知识
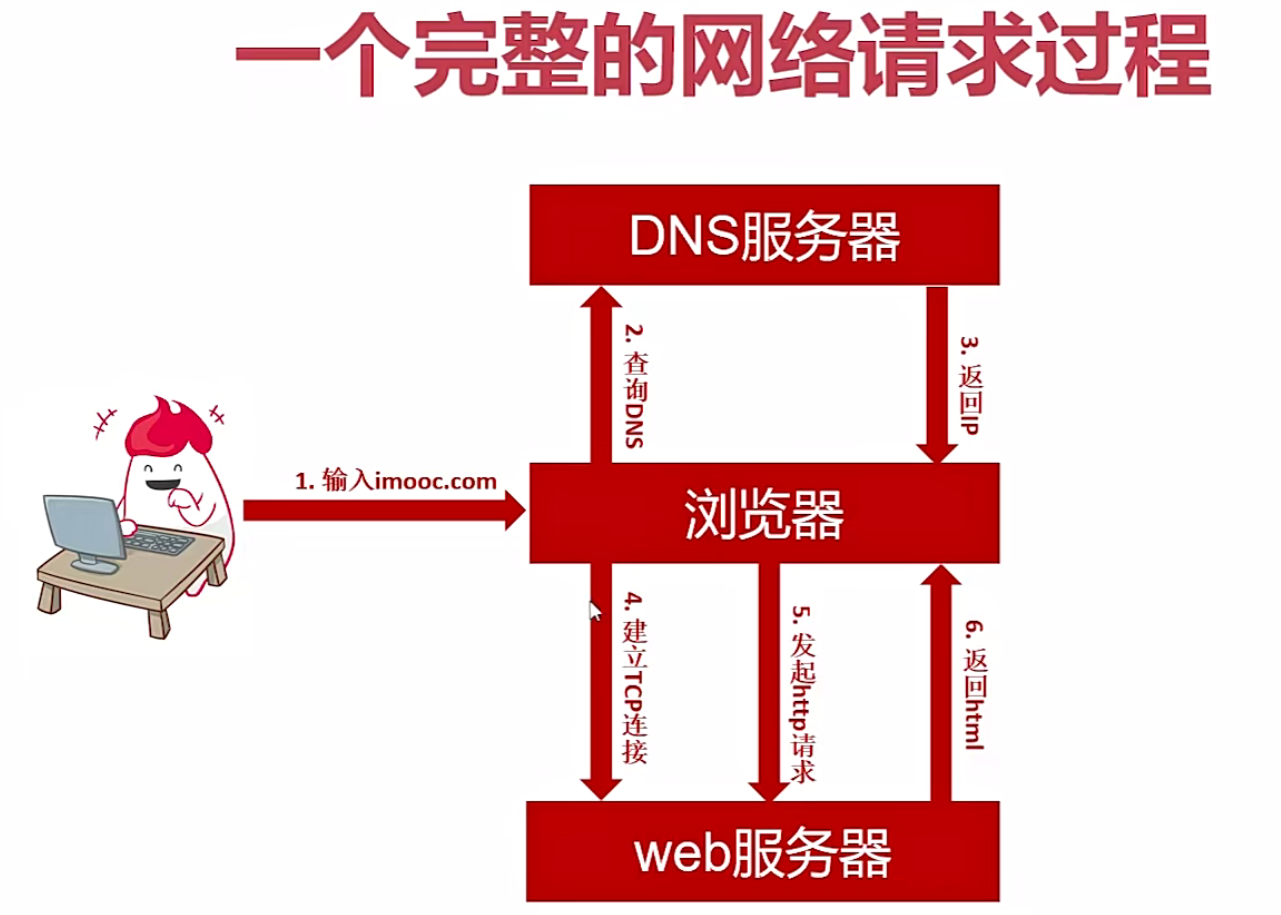
问题一:为什么服务器不会随便封禁ip或者ip段
原因主要有以下两点:
- DHCP,动态ip,我们日常的ip地址基本都是动态ip(静态ip需要花钱去买),同一台及其可能每天的ip都不一样
- 局域网,整个局域网可能对外只会存在一个公网ip,如果封禁,会导致整个局域网内所有用户均无法访问
url协议
其他概念比较熟悉,了解锚点的概念,可以定位到同一页面的某个位置

Socket编程
了解即可
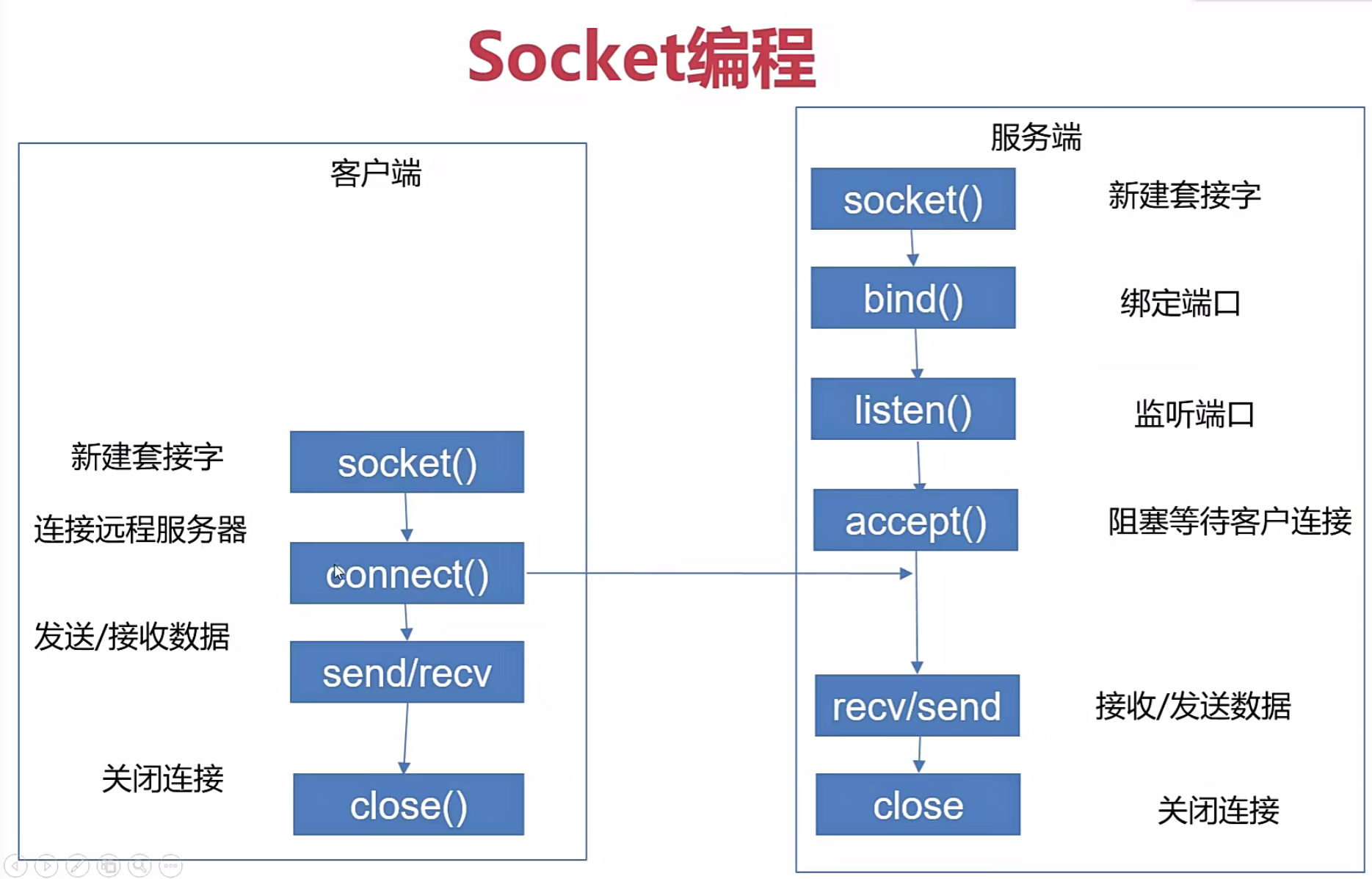
注意:recv、accept等方法都是阻塞式方式
前端知识
html(网页基础骨架)+css(网页装饰)+js(网页交互)
浏览器加载过程:

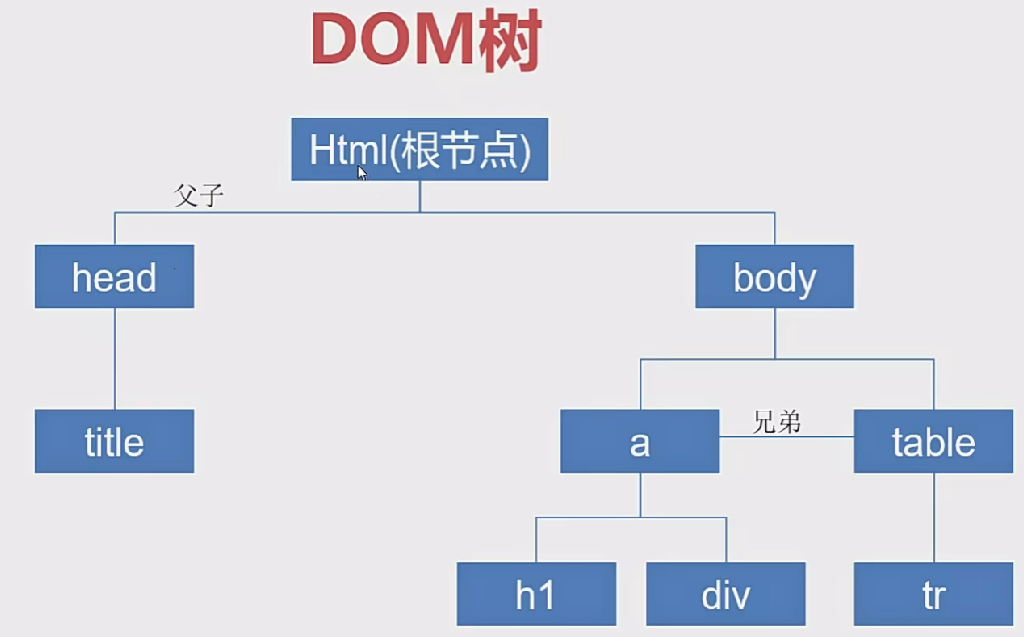
dom树:
可以根据dom树定位特定元素节点,javaScript操控html本质就是通过dom树来实现的
了解标签选择器、id选择器和class选择器的概念,很多动态网页都是依靠js来动态生成的html
AJAX & json & xml
AJAX = 异步JavaScript+XML
AJAX是一种无需重新加载整个页面的情况下,能够更新部分网页的技术
json和xml的产生背景:
- 跨语言的数据格式 (不同语言编写服务之间的数据传输问题)
- 可以通过响应头 content-type字段指明数据为json格式
jquery等框架都提供了对应API去构造AJAX请求
动态网页 vs 静态网页

GET VS POST请求

数据传输格式 content-type

<img src="02%20%E7%88%AC%E8%99%AB%E6%A6%82%E8%BF%B0/image-20240515104635902.png" alt="image-20240515104635902" style="zoom:50%;" />
前端数据提交方式:
- form表单的submit
- js监听事件的方式
- button按钮点击事件的方式
- js发送AJAX请求的方式
爬虫数据采集分类
按照采集对象分类:
- 全网采集:一般只有搜索引擎浏览器才会这么做
- 全站采集:对某个网站所以数据采集,一般需求也不多
- 具体网站指定数据采集:这种需求最多,一般应用只会对网站的某个具体数据感兴趣
按照采集方案分类:
- 利用http协议采集—页面分析
- 利用api接口采集—app数据采集
- 利用目标网站的api采集—微博、github、twitter、facebook等,这些大型网站用于一般有开放的api平台,可以供第三方开发者扩展使用
对于99%以上的网站都不会对外提供api,所以绝大多数情况只能利用http请求,对网页进行分析
requests库
知道如何构造请求、伪造请求头、获取请求、解析请求,详细教程参考官方文档即可
数据解析手段
正则表达式
正则表达式语法参照菜鸟教程 正则表达式 - 教程
python提供了re来进行正则化操作,具体用法参照菜鸟教程-Python 正则表达式,可以实现替换、搜索、提取数据的功能
beautifulsoup
python中用于解析html的库
xpath
*XPath 是一门在 XML 文档中查找信息的语言。,Xpath详细概念介绍
视频教程,讲的比较好
python中支持xPath的库:
- lxml:文档不友好,不推荐
- scrapy selector:是对lxml的再次封装
浏览器可以为我们自动生成想要的xpath表达式,流程如下图所示:
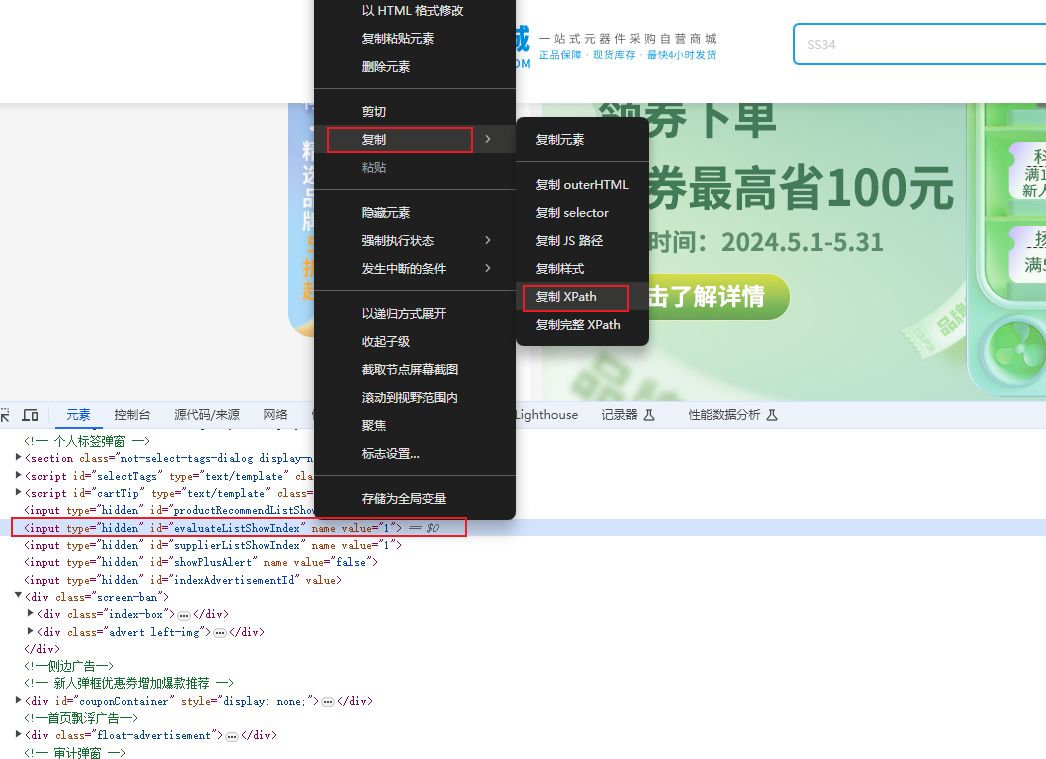
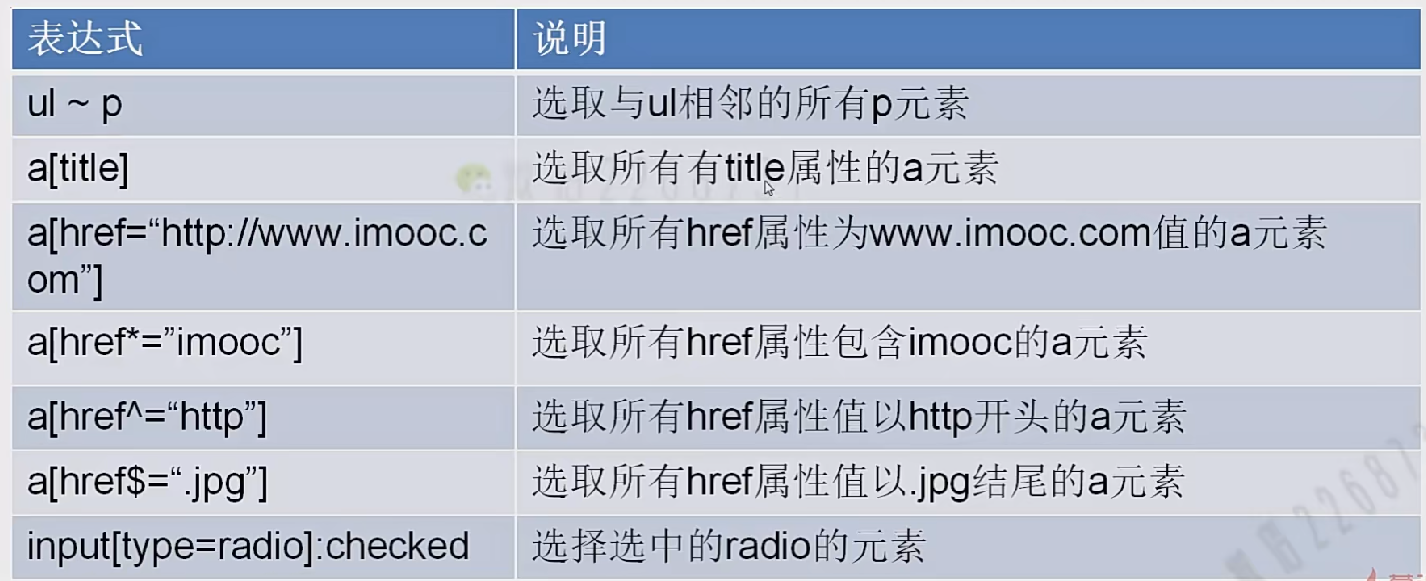
css选择器
在python中推荐使用scrapy中的Selector,参考博客


 微信
微信 支付宝
支付宝
